As I was working on a research project with graduate students, I became interested in fast and not necessarily very accurate approximations to the normal cdf Φ and its inverse. Reading through this 2010 paper of Richards et al., using for instance Polya’s
(with another version replacing 2/π with the squared root of π/8) and
not to mention a rational faction. All of which are more efficient (in R), if barely, than the resident pnorm() function.
I am currently preparing a survey paper on the present state of computational statistics, reflecting on the massive evolution of the field since my early Monte Carlo simulations on an Apple //e, which would take a few days to return a curve of approximate expected squared error losses… It seems to me that MCMC is attracting more attention nowadays than in the past decade, both because of methodological advances linked with better theoretical tools, as for instance in the handling of stochastic processes, and because of new forays in accelerated computing via parallel and cloud computing, The breadth and quality of talks at MCMski IV is testimony to this. A second trend that is not unrelated to the first one is the development of new and the rehabilitation of older techniques to handle complex models by approximations, witness ABC, Expectation-Propagation, variational Bayes, &tc. With a corollary being an healthy questioning of the models themselves. As illustrated for instance in Chris Holmes’ talk last week. While those simplifications are inevitable when faced with hardly imaginable levels of complexity, I still remain confident about the “inevitability” of turning statistics into an “optimize+penalize” tunnel vision… A third characteristic is the emergence of new languages and meta-languages intended to handle complexity both of problems and of solutions towards a wider audience of users. STAN obviously comes to mind. And JAGS. But it may be that another scale of language is now required…
If you have any suggestion of novel directions in computational statistics or instead of dead ends, I would be most interested in hearing them! So please do comment or send emails to my gmail address bayesianstatistics…
Michael Blum and Olivier François, along with Katalin Csillery, just released an R package entitled abc. (I am surprised the name was not already registered!) Its aim is obviously to implement ABC approximations for Bayesian inference:
Description The ’abc’ package provides various functions for parameter estimation and model selection in an ABC framework. Three main functions are available: (i) ’abc’ implements several ABC inference algorithms, (ii) ’cv4abc’ is a cross-validation tool to evaluate the quality of the estimation and help the choice of tolerance rate, and (iii) ’postpr’ implements model selection in an ABC setting. All these functions are accompanied by appropriate summary and plotting functions.
The core abc function starts from simulated samples (from the prior and from the sampling distribution) and elaborates on the standard hard-thresholding found in the basic ABC algorithm. The extensions use nonparametric perspectives defended by Blum and Francois that I think are appropriate in this setting. Other major functions include a cross-validation procedure for selecting the threshold and an application that computes posterior probabilities of models under competition, using the conglomerate of summary statistics across models. (As in our paper with Jean-Marie Cornuet, Aude Grelaud, and Jean-Michel Marin.) I have not had time yet to experiment with the package, however I can testify the manual is well-written!
First, Peter Grünwald had to cancel his lectures at Yes III due to a severe flu, which was unfortunate both for him (!) and for the participants to the workshop. Indeed, I was quite interested in hearing about the/his latest developments on the minimum length encoding priors… The lectures by Laurie Davies and Niels Hjort did take place, however, and were quite informative from my perspective: Laurie Davies gave a very general lecture on the notion of approximation and regularisation in Statistics, with a lot of good questions about the nature of “truth” and “model”, which was quite appropriate for this meeting. There also was a kind of ABC flavour in his talk—which made a sort of a connection with mine—, in that models were generally tested by running virtual datasets and checking for adequacy of the observed model. Maybe a bit too ad-hoc and frequentist, as well as fundamentally dependent on the measure of adequacy (in a Vapnik-Cervonenkis sense), but still very interesting. (Of course, a Bayesian answer would also incorporate the consequence of a rejection by looking at the action under the alternative/rejection…) The second half of his lectures was about non-parametric regression, a topic I always find incompletely covered as to why and where the assumptions are made. But I think these lectures must have had a lasting impact on the young statisticians attending the workshop.
Niels Hjort first talked about the “quiet scandal of Statistics”, a nice sentence coined by Leo Breiman, which actually replies to some extent to the previous lectures in that he complained about the lack of accounting for the randomness/bias in selecting a model before working with it as if it was the “truth”. Another very interesting part of the lectures was dealing with his focussed information criterion (FIC), which adds to the menagerie of information criteria, but also has an interesting link with the pre-test and shrinkage literature of the 70’s and the 80’s. Selecting a model according to its estimated performances in terms of a common loss function is certainly of interest, even though incorporating everything within a single Bayesian framework would certainly be more coherent. Niels also included a fairly exciting data analysis about the authorship of the Novel Prize novel “Quiet flows the Don“, which he attributed to the Nobel Prize winner Sholokhov (solely on the basis of the length of the sentences). Most of his lecture covers material related to his recent book Model Selection and Model Averaging co-authored with Gerda Claeskens.
My only criticism about the meeting is that, despite the relatively small audience, there was little interaction and discussion during the talks (which makes sense for my talk as there was hardly anyone, besides Nils Hjort, interested in computational Bayes!). The questions during the talks were mostly asked by the three senior lecturers and the debates as well. This certainly occurs in other young statisticians meetings, but I think the audience should be encouraged to participate, to debate and to criticise, because this is part of the job of being a researcher. Having for instance registered discussants would help.
Another personnal regret is to have missed the opportunity to attend a concert of Jordi Savall who was playing on Tuesday night Marais’ Lecons de Ténèbres in Eindhoven…

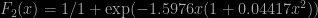
![F_0^{-1}(p) =(-\pi/2 \log[1-(2p-1)^2])^{\frac{1}{2}}](https://s0.wp.com/latex.php?latex=F_0%5E%7B-1%7D%28p%29+%3D%28-%5Cpi%2F2+%5Clog%5B1-%282p-1%29%5E2%5D%29%5E%7B%5Cfrac%7B1%7D%7B2%7D%7D&bg=000000&fg=B0B0B0&s=0&c=20201002)

