testing via credible sets
Måns Thulin released today an arXiv document on some decision-theoretic justifications for [running] Bayesian hypothesis testing through credible sets. His main point is that using the unnatural prior setting mass on a point-null hypothesis can be avoided by rejecting the null when the point-null value of the parameter does not belong to the credible interval and that this decision procedure can be validated through the use of special loss functions. While I stress to my students that point-null hypotheses are very unnatural and should be avoided at all cost, and also that constructing a confidence interval is not the same as designing a test—the former assess the precision in the estimation, while the later opposes two different and even incompatible models—, let us consider Måns’ arguments for their own sake.
The idea of the paper is that there exist loss functions for testing point-null hypotheses that lead to HPD, symmetric and one-sided intervals as acceptance regions, depending on the loss func. This was already found in Pereira & Stern (1999). The issue with these loss functions is that they involve the corresponding credible sets in their definition, hence are somehow tautological. For instance, when considering the HPD set and T(x) as the largest HPD set not containing the point-null value of the parameter, the corresponding loss function is
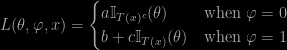
parameterised by a,b,c. And depending on the HPD region.
Måns then introduces new loss functions that do not depend on x and still lead to either the symmetric or the one-sided credible intervals.as acceptance regions. However, one test actually has two different alternatives (Theorem 2), which makes it essentially a composition of two one-sided tests, while the other test returns the result to a one-sided test (Theorem 3), so even at this face-value level, I do not find the result that convincing. (For the one-sided test, George Casella and Roger Berger (1986) established links between Bayesian posterior probabilities and frequentist p-values.) Both Theorem 3 and the last result of the paper (Theorem 4) use a generic and set-free observation-free loss function (related to eqn. (5.2.1) in my book!, as quoted by the paper) but (and this is a big but) they only hold for prior distributions setting (prior) mass on both the null and the alternative. Otherwise, the solution is to always reject the hypothesis with the zero probability… This is actually an interesting argument on the why-are-credible-sets-unsuitable-for-testing debate, as it cannot bypass the introduction of a prior mass on Θ0!
Overall, I furthermore consider that a decision-theoretic approach to testing should encompass future steps rather than focussing on the reply to the (admittedly dumb) question is θ zero? Therefore, it must have both plan A and plan B at the ready, which means preparing (and using!) prior distributions under both hypotheses. Even on point-null hypotheses.
Now, after I wrote the above, I came upon a Stack Exchange page initiated by Måns last July. This is presumably not the first time a paper stems from Stack Exchange, but this is a fairly interesting outcome: thanks to the debate on his question, Måns managed to get a coherent manuscript written. Great! (In a sense, this reminded me of the polymath experiments of Terry Tao, Timothy Gower and others. Meaning that maybe most contributors could have become coauthors to the paper!)

October 11, 2012 at 1:54 pm
Blogger doesn’t allow trackbacking, so here is a “manual” link to my blog response to your post :) http://lookingatdata.blogspot.se/2012/10/a-reply-to-testing-via-credible-sets.html
October 11, 2012 at 2:28 pm
Thanks! I do not know why the earlier comments did not make it! I will check in the spam list…
October 11, 2012 at 2:36 pm
They were indeed in the spam list, sorry about this!
October 8, 2012 at 9:16 am
Thank you for your thoughtful comments! I wholeheartedly agree with the sentiment that is important to encompass future steps as well – something that often seems to be forgotten.
I think that the fact that there are two alternatives (theta_0) in Theorem 2 may be a good thing, as many practitioners seem to use confidence intervals for directional conclusions anyway. (“The interval only contains positive values of theta, so we conclude that theta is non-zero and positive.”) It is therefore very much in line with what people tend to do in practice.
While Theorems 3 and 4 deal with composite hypotheses with positive prior probabilities (I realize know that this could be made clearer in the paper), Theorem 2 is concerned with point-null hypotheses, and allows for testing without a prior mass on the null… as long as the statistician is willing to accept that the decision to reject the null hypothesis always comes with additional information about in which direction it is rejected. The benefits of avoiding a prior mass on the null hypothesis include that you can use noninformative priors and avoid Lindley’s paradox.
Stack Exchange was a great resource for finding relevant papers when I started this research (although I didn’t realize at the time that it would turn into a research problem – I expected there to be a well-known solution!). It is certainly something that I can recommend to other researchers to try.