Unbiased Bayes for Big Data: Path of partial posteriors

“Data complexity is sub-linear in N, no bias is introduced, variance is finite.”
Heiko Strathman, Dino Sejdinovic and Mark Girolami have arXived a few weeks ago a paper on the use of a telescoping estimator to achieve an unbiased estimator of a Bayes estimator relying on the entire dataset, while using only a small proportion of the dataset. The idea is that a sequence converging—to an unbiased estimator—of estimators φt can be turned into an unbiased estimator by a stopping rule T:
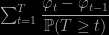
is indeed unbiased. In a “Big Data” framework, the components φt are MCMC versions of posterior expectations based on a proportion αt of the data. And the stopping rule cannot exceed αt=1. The authors further propose to replicate this unbiased estimator R times on R parallel processors. They further claim a reduction in the computing cost of

which means that a sub-linear cost can be achieved. However, the gain in computing time means higher variance than for the full MCMC solution:
“It is clear that running an MCMC chain on the full posterior, for any statistic, produces more accurate estimates than the debiasing approach, which by construction has an additional intrinsic source of variance. This means that if it is possible to produce even only a single MCMC sample (…), the resulting posterior expectation can be estimated with less expected error. It is therefore not instructive to compare approaches in that region. “
I first got a “free lunch” impression when reading the paper, namely it sounded like using a random stopping rule was enough to overcome unbiasedness and large size jams. This is not the message of the paper, but I remain both intrigued by the possibilities the unbiasedness offers and bemused by the claims therein, for several reasons:
- the above estimator requires computing T MCMC (partial) estimators φt in parallel. All of those estimators have to be associated with Markov chains in a stationary regime and they all are associated with independent chains. While addressing the convergence of a single chain, the paper does not truly cover the simultaneous convergence assessment on a group of T parallel MCMC sequences. And the paragraph below is further confusing me as it seems to imply that convergence is not that important thanks to the de-biasing equation. In fact, further discussion with the authors (!) led me to understand this relates to the existing alternatives for handling large data, like firefly Monte Carlo: Convergence to the stationary remains essential (and somewhat problematic) for all the partial estimators.
“If a Markov chain is, in line with above considerations, used for computing partial posterior expectations 𝔼πt[ϕ(θ)], it need not be induced by any form of approximation, noise injection, or state-space augmentation of the transition kernel. As a result, the notorious difficulties of ensuring acceptable mixing and problems of stickiness are conveniently side-stepped –which is in sharp contrast to all existing approaches.”
- the impact of the distribution of the stopping time T over the performances of the estimator is uncanny! Its tail should simply decreases more slowly than the square difference between the partial estimators. This requirement is both hard to achieve [given that the variances of the—partial—MCMC estimators are hard to assess] and with negative consequences on the overall computing time. The choice of the tail rate is thus quite delicate to validate against the variance constraints (2) and (3).
- the stopping time T must have a positive probability to take the largest possible value, corresponding to using the whole sample, in which case the approach gets worse than using directly the original MCMC algorithm, as noted on the first quote above. This shows (as stated in the first quote above) the approach cannot uniformly improve upon the standard MCMC.
- the comparison in the (log-)normal toy example is difficult to calibrate. (And why differentiating a log normal from a normal sample? and why are the tails extremely wide for 2²⁶ datapoints?) The number of likelihood evaluations is 5e-4 times smaller for the de-biased version, hence means a humongous gain in computing time, but how does this partial exploration of the information contained in the data impact the final variability of the estimate? If I judge from Figure 4 (top) after 300 replications, one still observes a range of 0.1 at the end of the 300 iterations. If I could produce the Bayes estimate for the whole data, the variability would be of order 2e-4… If the goal is to find an estimate of the parameter of interest, with a predetermined error, this is fine. But then the comparison with the genuine Bayesian answer is not very meaningful.
- when averaging the unbiased estimators R times, it is unclear whether or not the same subset of nt datapoints is used to compute the partial estimator φt. On the one hand, using different subsets should improve the connection with the genuine Bayes estimator. On the other hand, this may induce higher storage and computing costs.
- cases when the likelihood does not factorise are not always favourable to the de-biasing approach (Section 5.1) in that the availability of the joint density of a subset of the whole data may prove an issue. Take for instance a time series or a graphical network. Computing the joint density of a subset requires stringent conditions on the way the subset is selected.
Overall, I think I understand the purpose of the paper better now I have read it a few times. The comparison is only relevant against other limited information solutions. Not against the full Monty MCMC. However, in the formal examples processed in the paper, a more direct approach would be to compute (in parallel) MCMC estimates for increasing portions of the data, add a dose of bootstrap to reduce bias, and check for stabilisation of the averages.

March 22, 2015 at 3:25 pm
[…] Unbiased Bayes for Big Data: Path of partial posteriors. […]
March 17, 2015 at 11:21 am
[…] reply to Christian’s critique was also featured. […]
February 26, 2015 at 2:47 pm
The debiasing method applied to expectations w.r.t. to Markov chain stationary distributions is Rhee and Glynn (http://arxiv.org/abs/1409.4302), which Agapiou et al. upon and generalize to infinite dimensional models (http://arxiv.org/abs/1411.7713)….
February 26, 2015 at 12:03 pm
Since φt is indeed an MCMC version of the posterior expectation of φ with respect to πt, it has the standard MCMC bias. To get rid of this bias, the paper suggests (in the paragraph “MCMC and finite time bias”) using another debiasing technique presented here.
It is not clear that both of these methods can be combined while still guaranteeing a reasonable computational cost and variance.
Unless those two things are successfully combined, the use of the term “unbiased” is a bit shocking: their proposed estimator is biased. I would have expected the paper to fully explore these debiasing techniques before claiming anything. Now who’s going to do that, when this “half-baked” paper is online? With all due respect to the authors who are super inventive, nice and clever people (trying to save my career here), I bet no one is going to check that, and so the idea has been “killed in the egg”.
Another thing that shocked me (am I easily shocked!?) is that Rhee did his PhD thesis on the idea of “perfect estimation” instead of “perfect sampling”. Hence when the introduction of the paper states “In this contribution, we propose a different view on the problem. We construct a scheme that directly estimates posterior expectations with neither simulation from the full posterior nor construction of alternative approximate transition kernels – without introducing bias.” then really the view should be attributed to Rhee & Glynn.
February 26, 2015 at 3:10 pm
Thanks for these very useful and constructive comments, Pierre!
I agree that the “Unbiased” in the title may be misleading and it was certainly not our intention to claim that we get around the MCMC bias, and we discuss this on page 6. We were trying to contrast our approach to the growing body of work that uses approximate transition kernels and therefore introduces additional bias that is very difficult to quantify. Posting the early draft on arxiv precisely had a point of encouraging open discussions like this, and to let the advantages and vulnerabilities of different approaches be subject to an open criticism: should we mess with the transition kernel? do we care about simulation or estimation? do we care about bias? do we really want to be fully Bayesian when we have a lot of data?
In terms of the second point, I was hoping that the paper had a clear attribution of the main idea to the seminal work of Rhee & Glynn. On page 2, we have the following paragraph:
“Our work builds on several breakthroughs in related areas, such as unbiased estimation for stochastic differential equations (Rhee and Glynn, 2013) and for Markov chain equilibrium expectations (Glynn and Rhee, 2014). These developments demonstrate the overarching principle that estimation is often an easier problem than simulation – a dictum we adopt and apply here in the context of Bayesian inference.”
Perhaps, the current draft has not emphasised this enough – next version will certainly rectify this.
February 26, 2015 at 5:49 pm
Cheers Dino, I look forward to the future developments of this project!
February 26, 2015 at 12:48 am
This is a neat paper, but I’m not sold on the underlying assumption that “unbiased but higher variance” is better than biased. I mean, people keep on saying it (more so since I moved to Warwick than at any other time, but that’s neither here nor there), but I’ve not seen an enormous wealth of evidence to back it up.
Hence I agree that the comparisons with other unbiased methods are the absolute wrong comparisons to make. People do “big data” / “big model” computations every day on data at least as large and complex as the ones in this paper using inexact (and it’s not even worth putting the scare quotes around that – just because your method is asymptotically unbiased doesn’t guarantee it’s any good in a finite computational budget) methods. I fear the situation that I ran into walking out of a recent conference session of Bayesian image analysis and hearing a person ask “why are they solving problems from the 80s with methods from the 90s?”.
I’m also slightly scared that the finite variance condition seems to require us to know more about the mixing and convergence of MCMC than we really know. But this could be me misunderstanding the condition in the paper (from my reading, to ensure it you need a non-asymptotic bound on the distance from the target). It also suggests that if the problem misbehaves (you are, for example, using a cheap but inefficient MCMC scheme for reasons of parallel scaling), the truncation time could be mammoth.
February 26, 2015 at 2:04 am
I hope someone give a talk titled “The road to big data is paved with partial posteriors”. It nicely sets up a metaphor for “big data” and “partial posteriors” :p
February 26, 2015 at 12:46 pm
I’ve been thinking similarly about de-biasing things. I think the need for unbiasedness in pseudo-marginal type schemes may have overemphasised its importance – in general unbiasedness certainly isn’t the be all and end all, and unless it’s a requirement for an estimator then really there is probably a more appropriate loss function to minimise (mean squared error or similar).
February 26, 2015 at 12:48 am
Why should we abandon the Nice bias of the good scientist?
C