Archive for puzzle
who’s that travelling salesman path?!
Posted in Statistics with tags image processing, puzzle, StippleGen, travelling salesman on July 18, 2017 by xi'an
Asher’s enigma
Posted in R, Statistics with tags beta distribution, puzzle, R-bloggers, unit square on July 26, 2010 by xi'anOn his Probability and statistics blog, Matt Asher put a funny question (with my rephrasing):
Take a unit square. Now pick two spots at random along the perimeter, uniformly. For each of these two locations, pick another random point from one of the three other sides of the square and draw the segment. What is the probability the two segments intersect? And what is the distribution for the intersection points?
The (my) intuition for the first question was 1/2, but a quick computation led to another answer. The key to the computation is to distinguish whether or not both segments share one side of the square. They do with probability
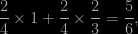
in which case they intersect with probability 1/2. They occupy the four sides with probability 1/6, in which case they intersect with probability 1/3. So the final answer is 17/36 (as posted by several readers and empirically found by Matt). The second question is much more tricky: the histogram of the distribution of the coordinates is peaked towards the boundaries, thus reminding me of an arc-sine distribution, but there is a bump in the middle as well. Computing the coordinates of the intersection depending on the respective positions of the endpoints of both segments and simulating those distributions led me to histograms that looked either like beta B(a,a) distributions, or like beta B(1,a) distributions, or like beta B(a,1) distributions… Not exactly, though. So not even a mixture of beta distributions is enough to explain the distribution of the intersection points… For instance, the intersection points corresponding to segments were both segments start from the same side and end up in the opposite side are distributed as

where all u‘s are uniform on (0,1) and under the constraint 
 The R code is
The R code is
u=matrix(runif(4*10^5),ncol=4)
u[,c(1,3)]=t(apply(u[,c(1,3)],1,sort))
u[,c(2,4)]=-t(apply(-u[,c(2,4)],1,sort))
y=(u[,1]*(u[,4]-u[,3])-u[,3]*(u[,2]-u[,1]))/(u[,1]+u[,4]-u[,2]-u[,3])
Similarly, if the two segments start from the same side but end up on different sides, the distribution of one coordinate is given by

under the constraint 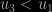
 The corresponding R code is
The corresponding R code is
u=matrix(runif(4*10^5),ncol=4)
u[,c(1,3)]=-t(apply(-u[,c(1,3)],1,sort))
y=(u[,1]*(1-u[,3])-u[,3]*u[,4]*(u[,2]-u[,1]))/(1-u[,3]-u[,4]*(u[,2]-u[,1]))
Le Monde rank test (corr’d)
Posted in R, Statistics with tags Le Monde, puzzle, R, Spearman rank test on April 7, 2010 by xi'anSince my first representation of the rank statistic as paired was incorrect, here is the histogram produced by the simulation
perm=sample(1:20) saple[t]=sum(abs(sort(perm[1:10])-sort(perm[11:20])))
when 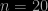
 An interesting change is that the regression of the log-mean on
An interesting change is that the regression of the log-mean on 
> lm(log(memean)~log(enn)) Call: lm(formula = log(memean) ~ log(enn)) Coefficients: (Intercept) log(enn) -1.162 1.499
meaning that the mean is in 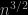

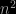
> summary(lm(memean~eth-1))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
eth 0.3117990 0.0002719 1147 <2e-16 ***
with a very good fit.

Le Monde rank test
Posted in R, Statistics with tags climate change, climatosceptic, correlation, global warming, Le Monde, puzzle, R, Robin Ryder, Spearman rank test on April 5, 2010 by xi'anIn the puzzle found in Le Monde of this weekend, the mathematical object behind the silly story is defined as a pseudo-Spearman rank correlation test statistic,
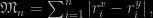
where the difference between the ranks of the paired random variables 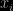
perm=sample(1:20) saple[t]=sum(abs(perm[1:10]-perm[11:20]))
![]() When regressing the mean of this statistic
When regressing the mean of this statistic 
![\mathbb{E} [\mathfrak{M}_n] \approx 0.1681 n^2 - 0.3769 n + 11.1921](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D+%5B%5Cmathfrak%7BM%7D_n%5D+%5Capprox+0.1681+n%5E2+-+0.3769+n+%2B+11.1921&bg=000000&fg=B0B0B0&s=0&c=20201002)
which does not translate into a nice polynomial in
Another interesting probabilistic/combinatorial problem issued from an earlier Le Monde puzzle: given an urn with 

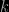

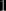

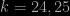
Ps- The same math tribune in Le Monde coincidently advertises a book, Le Mythe Climatique, by Benoît Rittaud that adresses … climate change issues and the “statistical mistakes made by climatologists”. The interesting point (if any) is that Benoît Rittaud is a “mathematician not a statistician”, with a few papers in ergodic theory, but this advocated climatoskeptic nonetheless criticises the use of both statistical and simulation tools in climate modeling. (“Simulation has only been around for a few dozen years, a very short span in the history of sciences. The climate debate may be an opportunity to reassess the role of simulation in the scientific process.”)
New Le Monde puzzle
Posted in Kids, R with tags Le Monde, puzzle on March 4, 2010 by xi'anWhen I first read Le Monde puzzle this weekend, I though it was even less exciting than the previous one: find


such that
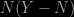

The solution is obtained by brute-force checking through an R program:

and then the a next solution is 
However, while waiting in the plane to Edinburgh, I thought more about it and found that the problem can be solved with paper and pencil. It goes like this. There exists an integer

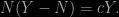
Hence, solving the second degree equation,
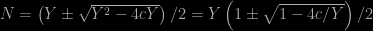
which implies that

is one of the integral factors of

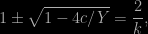
we get

and thus
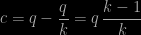
We thus deduce that 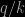
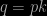
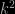

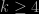
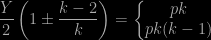
The conclusion is thus that any 

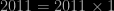

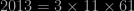

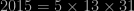
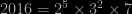
we see (without any R programming) that 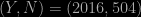
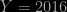
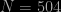
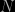

An approach avoiding the second degree equation is to notice that 


which implies

thus that