What are the distributions on the positive k-dimensional quadrant with parametrizable covariance matrix? (bis)
Wondering about the question I posted on Friday (on StackExchange, no satisfactory answer so far!), I looked further at the special case of the gamma distribution I suggested at the end. Starting from the moment conditions,


and

the [corrected, thanks to David Epstein!] solution is (hopefully) given by the system
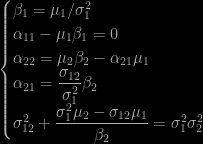
The resolution of this system obviously imposes conditions on those moments, like
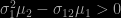
So I ran a small R experiment checking when there was no acceptable solution to the system. I started with five moments that satisfied the basic Stieltjes and determinant conditions
# basically anything mu=runif(2,0,10) # Jensen inequality sig=c(mu[1]^2/runif(1),mu[2]^2/runif(1)) # my R code returning the solution if any sol(mu,c(sig,runif(1,-sqrt(prod(sig)),sqrt(prod(sig)))))
and got a fair share (20%) of rejections, e.g.
> sol(mu,c(sig,runif(1,-sqrt(prod(sig)),sqrt(prod(sig))))) $solub [1] FALSE $alpha [1] 0.8086944 0.1220291 -0.1491023 $beta [1] 0.1086459 0.5320866
However, not being sure about the constraints on the five moments I am now left with another question: what are the necessary and sufficient conditions on the five moments of a pair of positive vectors?! Or, more generally, what are the necessary and sufficient conditions on the k-dimensional μ and Σ for them to be first and second moments of a positive k-dimensional vector?

April 8, 2012 at 12:13 am
[…] Universidade de São Paulo, Brazil) has posted an answer to my earlier question both as a comment on the ‘Og and as a solution on StackOverflow (with a much more readable LaTeX output). His solution is based […]
April 5, 2012 at 1:01 am
Dear Xi’an,
I’m not sure if the following helps with your question. Suppose that we have a multivariate normal random vector

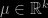 and $k\times k$ symmetric positive definite matrix
and $k\times k$ symmetric positive definite matrix 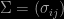 .
.
with
For this lognormal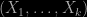 we have
we have
![m_i := E[X_i] = e^{\mu_i + \sigma_{ii}/2} \, , \quad i=1,\dots,k\, ,](https://s0.wp.com/latex.php?latex=m_i+%3A%3D+E%5BX_i%5D+%3D+e%5E%7B%5Cmu_i+%2B+%5Csigma_%7Bii%7D%2F2%7D+%5C%2C+%2C+%5Cquad+i%3D1%2C%5Cdots%2Ck%5C%2C+%2C+&bg=000000&fg=B0B0B0&s=0&c=20201002)
![c_{ij} := Cov[X_i,X_j] = m_i \,m_j \,(e^{\sigma_{ij}} - 1) \, , \quad i,j=1,\dots,k\, ,](https://s0.wp.com/latex.php?latex=c_%7Bij%7D+%3A%3D+Cov%5BX_i%2CX_j%5D+%3D+m_i+%5C%2Cm_j+%5C%2C%28e%5E%7B%5Csigma_%7Bij%7D%7D+-+1%29+%5C%2C+%2C+%5Cquad+i%2Cj%3D1%2C%5Cdots%2Ck%5C%2C+%2C+&bg=000000&fg=B0B0B0&s=0&c=20201002)
 .
.
and it follows that
So, we can ask the converse question: given and
and 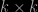 symmetric positive definite matrix
symmetric positive definite matrix  , satisfying
, satisfying  , if we let
, if we let
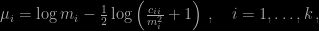

we will have a lognormal vector with the prescribed means and covariances.
Regards,
Paulo.
P.S. The constraint on is equivalent to
is equivalent to ![\mathbb{E}[X_i X_j]\ge 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BX_i+X_j%5D%5Cge+0&bg=000000&fg=B0B0B0&s=0&c=20201002) .
.
April 5, 2012 at 9:59 pm
Terrific! You should also post the reply on StackOverflow, this answers my question!!!
April 6, 2012 at 12:56 am
Ok, done!
April 4, 2012 at 3:04 am
I have opened a question on math.se http://math.stackexchange.com/questions/127813/what-are-the-restrictions-on-the-covariance-matrix-of-a-nonnegative-multivariate
I suspect that someone there may be able to answer your initial question as well.
April 4, 2012 at 10:01 am
Thank you: I was planning to post this question myself, and would have preferred to do so, but this is not a major problem! We will see if this attracts more answers than my original question.
April 4, 2012 at 6:09 pm
I apologize.
One comment: Your R code does not seem to restrict the covariance of the two variables to be greater than -mu[1]mu[2]. This follows from Cov(X,Y) = E(XY)-E(X)E(Y) and the fact that XY is always nonnegative.