On particle learning
In connection with the Valencia 9 meeting that started yesterday, and with Hedie‘s talk there, we have posted on arXiv a set of comments on particle learning. The arXiv paper contains several discussions but they mostly focus on the inevitable degeneracy that accompanies particle systems. When Lopes et al. state that 

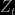

The graph above is an illustration of the degeneracy in the setup of a Poisson mixture with five components and 10,000 observations. The boxplots represent the variation of the evidence approximations based on a particle learning sample and Lopes et al. approximation, on a particle learning sample and Chib’s (1995) approximation, and on an MCMC sample and Chib’s (1995) approximation, for 250 replications. The differences are therefore quite severe when considering this number of observations. (I put the R code on my website for anyone who wants to check if I programmed things wrong.) There is no clear solution to the degeneracy problem, in my opinion, because the increase in the particle size overcoming degeneracy must be particularly high… We will be discussing that this morning.

November 10, 2010 at 12:23 am
[…] rejoinder to the discussion of his Valencia 9 paper has been posted. Since the discussion involved several points made by members of the CREST statistics lab (and covered the mixture paper as much as the Valencia […]
July 18, 2010 at 12:12 am
[…] major change is the elimination of reversible jump from the mixture chapter (to be replaced with Chib’s approximation) and from the time-series chapter (to be simplified into a birth-and-death process). Going back to […]