Effective sample size
 In the previous days I have received several emails asking for clarification of the effective sample size derivation in “Introducing Monte Carlo Methods with R” (Section 4.4, pp. 98-100). Formula (4.3) gives the Monte Carlo estimate of the variance of a self-normalised importance sampling estimator (note the change from the original version in Introducing Monte Carlo Methods with R ! The weight W is unnormalised and hence the normalising constant
In the previous days I have received several emails asking for clarification of the effective sample size derivation in “Introducing Monte Carlo Methods with R” (Section 4.4, pp. 98-100). Formula (4.3) gives the Monte Carlo estimate of the variance of a self-normalised importance sampling estimator (note the change from the original version in Introducing Monte Carlo Methods with R ! The weight W is unnormalised and hence the normalising constant 
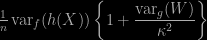
as

Now, the front term is somehow obvious so let us concentrate on the bracketed part. The empirical variance of the 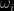

the coefficient 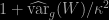

which leads to the definition of the effective sample size
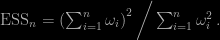
The confusing part in the current version is whether or not we use normalised W’s and

April 20, 2014 at 4:59 am
Just to clarify, W is *not* normalized, but little omega is?
Thanks