A misleading title…
When I received this book, Handbook of fitting statistical distributions with R, by Z. Karian and E.J. Dudewicz, from/for the Short Book Reviews section of the International Statistical Review, I was obviously impressed by its size (around 1700 pages and 3 kilos…). From briefly glancing at the table of contents, and the list of standard distributions appearing as subsections of the first chapters, I thought that the authors were covering different estimation/fitting techniques for most of the standard distributions. After taking a closer look at the book, I think the cover is misleading in several aspects: this is not a handbook (a.k.a. a reference book), it does not cover standard statistical distributions, the R input is marginal, and the authors only wrote part of the book, since about half of the chapters are written by other authors…
“The system we develop in this book has its origins in the one-parameter lambda distribution proposed by John Tukey.” Z.A. Karian & E.J. Dudewicz, p.3, Handbook of fitting statistical distributions with R
So I am glad I left Handbook of fitting statistical distributions with R in my office rather than dragging it along across the Caribbean! First, the book indeed does not aim at fitting standard distributions but instead at promoting a class of quantile distributions, the generalised lambda distributions (GLDs), whose quantile function is a location-scale transform of
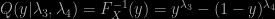
(under the constraint on the parameters that the above function of y is non-decreasing for a positive scale and non-increasing otherwise) and that the authors have been advocating for a long while. There is nothing wrong per se with those quantile distributions, but neither is there a particular reason to prefer them over the standard parametric distributions! Overall, I am quite wary of one-fits-all distributions, especially when they only depend on four parameters and mix finite with infinite support distributions. The lack of natural motivations for the above is enough to make fitting with those distributions not particularly compelling. Karian and Dudewicz spend an awful lot of space on numerical experiments backing their argument that the generalised lambda distributions approximate reasonably well (in the L1 and L2 norms, as it does not work for stricter norms) “all standard” distributions, but it does not explain why the substitution would be of such capital interest. Furthermore, the estimation of the parameters (i.e. the fitting in fitting statistical distributions) is not straightforward. While the book presents the density of the generalised lambda distributions as available in closed form (Theorem 1.2.2), namely (omitting the location-scale parameters),
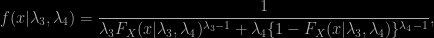
it fails to point out that the cdf

itself is not available in closed form. Therefore, neither likelihood estimation nor Bayesian inference seem easily implementable for those distributions. (Actually, a mention is made of maximum likelihood estimators for the first four empirical moments in the second chapter, but it is alas mistaken.) [Obviously, given that quantile distributions are easy to simulate, ABC would be a manageable tool for handling Bayesian inference on GLDs…] The book focus instead on moment and percentile estimators as the central estimation tool, with no clear message on which side to prefer (see, e.g., Section 5.5).
A chapter (by Su) covers the case of mixtures of GLDs, whose appeal is similarly lost on me. My major issue with using such distributions in mixture setting is that some components may have a finite support, which makes the use of score equations awkward and of Kullback-Leibler divergences to normal mixtures fraught with danger (since those divergence may then be infinite). The estimation method switches to maximum likelihood estimation, as presumably the moment method gets too ungainly. However, I fail to see how maximum likelihood is implemented: I checked the original paper by Su (2007), documenting the related GLDEX R function, but the approach is very approximate in that the true percentiles are replaced with pluggin (and fixed, i.e. non-iterative) values (again omitting the location-scale parameters)

in the likelihood function

A further chapter is dedicated to the generalised beta distribution, which simply is a location-scale transform of the regular beta distribution (even though it is called the extended GLD for no discernible reason). Again, I have nothing for or against this family (except maybe that using a bounded support distribution to approximate infinite support distributions could induce potential drawbacks…) I simply cannot see the point in multiplying parametric families of distributions where there is no compelling property to do so. (Which is also why as an editor/aeditor/referee, I have always been ultra-conservative vis-à-vis papers introducing new families of distributions.)
The R side of the book (i.e. the R in fitting statistical distributions with R) is not particularly appealing either: in the first chapters, i.e. in the first hundred pages, the only reference to R is the name of the R functions found on the attached CD-ROM to fit GLDs by the method of moments or of percentiles… The first detailed code is found on pages 305-309, but it is unfortunately a MATLAB code! (Same thing in several subsequent chapters.) Even though there is an R component to the book thanks to this CD-ROM, the authors could well be suspected of “surfing the R wave” of the Use R! and other “with R”collections. Indeed, my overall feeling is that they are mostly recycling their 2000 book Fitting statistical distributions into this R edition. (For instance, figures that are reproduced from the earlier book, incl. the cover, are not even produced with R. Most entries of the table of contents of Fitting statistical distributions are found in the table of contents of Handbook of fitting statistical distributions with R. The codes were then written in Maple and some Maple codes actually survive in the current version. Most of the novelty in this version is due to the inclusion of chapters written by additional authors.)
“It remains for a future research topic as to how to improve the generalized bootstrap to achieve a 95% confidence interval since 40% on average and 25%-55% still leaves room for improvement.” W. Cai & E.J. Dudewicz, p.852, Handbook of fitting statistical distributions with R
As in the 2000 edition, the “generalised bootstrap” method is argued as an improvement over the regular bootstrap, “fraught with danger of seriously inadequate results” (p.816), and as a mean to provide confidence assessments. This method, attributed to the authors in 1991, is actually a parametric bootstrap used in the context of the GLDs, where samples are generated from the fitted distribution and estimates of the variability of estimators of interest are obtained by a sheer Monte Carlo evaluation! (A repeated criticism of the bootstrap is its “inability to draw samples outside the range of the original dataset” (e.g., p.852). It is somehow ironical that the authors propose to use instead parameterised distributions whose support may be bounded.)
Among the negative features of the book, I want to mention the price ($150!!!), the glaring [for statisticians!] absence of confidence statements about the (moment and percentile) estimations (not to be confused with goodness-of-fit)—except for the much later chapter on generalised bootstrap—, the fact that the book contains more than 250 pages of tables—yes, printed tables!—including a page with a few hundred random numbers generated from a given distribution, the fact that the additional authors who wrote the contributed chapters are not mentioned elsewhere that in the front page of those chapters—not even in the table of contents!—, [once more] the misleading use of the term handbook in the title, the way Wiktionary defines it
handbook (plural handbooks)
- A topically organized book of reference on a certain field of knowledge, disregarding the size of it.
as it is not a “reference book”, nor a “topically organised book”: a newcomer opening Handbook of fitting statistical distributions with R cannot expect to find the section that would address her or his fitting problem, but has to read through the (first part) book in a linear way… So there is no redeeming angle there that could lead me to recommend Handbook of fitting statistical distributions with R as fitting any purpose. Save the trees!

March 2, 2014 at 8:01 am
For those interested in regression, there is actually a paper coming out in Statistics & Computing on using GLD for regression analysis, which can in fact, can provide a robust line beyond the capabilities of techniques like quantile regression or robust regression *and* with the property of zero mean residuals, which is unattainable by either of the aforementioned techniques.
I think rather than being an arm chair expert on GLD, the best way to actually try some of the packages like GLDEX and see how well the technique fits empirical data. It seems to me, the author of this post just read and formed his opinion, without actually trying to see whether the technique actually work…
April 28, 2013 at 3:46 pm
Thanks for reviewing the book! Which book(s) would you instead suggest, that describe algorithms/methods to fit data to statistical distributions (discrete and continuous). I am new to this field and I am trying to learn this area.
Thanks in advance!
Krishna
March 1, 2012 at 1:30 am
This handbook was actually produced in a hurry, Professor Dudewicz died of cancer shortly after the book was published. So I can understand, in some aspects, this book may be lacking in some details.
GLD is actually quite flexible in terms of fitting distribution to data, try fitting this distribution this with some real life data using gld or GLDEX package and you can see that it tends to fit data fairly well. The benefit of GLD comes from the fact we can often approximate the density of our data without having to try lots of different distributions. Don’t forget that in real life, you are not going to know the true distribution. So if you want to estimate the distribution, it would often be better to choose a flexible distribution.
Why would it be beneficial to fit a distribution to data? In many ways, if you can do this reasonably accurately, you can get all the statistical properties under one roof. You can get mean, variance, median, quantiles, whereas currently, you often need to use different statistical techniques to get different statistical properties of the data. E.g. you might estimate the sample mean, but you might estimate the density using kernel density estimation. It would be much more elegant just to fit a distribution and get all the estimated statistical properties in one go.
I like to point out that MLE is not the only way to fit GLD, you can also fit GLD using L moments and other methods. And actually, MLE is not that difficult to achieve, the real difficulty is to find suitable initial values, but this is the same problem for *many* numerical estimation problems and a solution has been proposed in Su (2007) in CDSA.
Of course the fitting method is going to be approximate, but the question is whether it is a sufficiently good estimate (and this is something we check using QQ plots, goodness of fit test etc…) In fact, a number of estimation methods to fit GLD to data is now available in GLDEX package, which incidentally is also covered in this book.
The chapter on fitting mixture was not by Su, it was by Ning, Gao and Dudewicz. A newcomer to this area could just read Su (2007) in JSS or the chapter on using GLDEX and start using the package to fit GLD to data. Also, the book contains a number of applications of GLD which the reviewer never commented on…
There are things I dislike about the book also, there does not seem to be a very integrated effort on distributional fitting methods for GLD and others, as there are different approaches and some approaches used the original Karian and Dudewicz’s prior work and there could have been a better flow between them. The tables are probably not needed given the electronic age we live in (it can be stored electronically) and they are based on a particular method which is known to be unstable. (i.e. fitting method of moments does not mean a good fit to the overall distribution)
As for saving a tree, you can just buy the ebook version :)
I think as researchers, we all have our own judgement about what is useful and what is not, however given GLD has been used in various disciplines over the years, I think it is unfair to create an impression that GLD is totally useless from this review.
March 6, 2012 at 10:46 pm
I understand your position but I remain unconvinced: GLD’s are parametric distributions, thus not universally able to model any situation. They are also mostly implicit in that, while simulation is straightforward, inference is hard for the lack of closed-form likelihood. The last point is about interpretation: once a dataset is fitted with a GLD, what else can be said about the underlying phenomenon?
October 7, 2012 at 6:39 am
I am not an expert of GLD at all, so i have a few questions on it:
1. For any estimation method, e.g. MLE, L-moments, can we calculate standard error so as to construct confidence interval or perform hypothesis testing?
2. Can we use GLD within, say, regression analysis? If yes, given its complexity, what is the gain of using it? As far as I know, many regression models are robust to error distribution when sample size is moderate. I ask this question because in all my work I am more interested in the ‘structure’ or ‘pattern’ exhibited in the data so I never need to fit a distribution to the data ONLY.
October 7, 2012 at 7:34 am
1. This is too broad a question for me to answer [here]! Given an estimation method, you may try to figure out the asymptotics of the estimator, which gives a first entry to confidence sets and testing. If this is not possible, bootstrap is often an answer, if not necessarily the most efficient.
2a. GLDs in regression: You have to understand that GLDs are particular parametric distributions. So, on principle, they can be used everywhere a normal distribution, say, is used. I personally do not see any gain in using it, but this is a personal opinion.
2b. I do not get your last point, however I think this is unrelated to GLDs per se, because of the previous reason. GLDs are not more or less robust than other families of distributions…
October 7, 2012 at 11:28 am
Thank you very much for your reply. I think I should have made my comments more clear.
1. I understand how to find asymptotic variance of MLE and bootstrap method in general (I got a phd in econometrics). However in the papers I found online, e.g. Lakhany&Mausser(2000), Tarsitano(2004) and Su(2007), most attention is paid on “fitting” and how good the (fitted) theoretical moments match the empirical ones, instead of the uncertainty of the resulting estimators. You also mentioned “the glaring absence of confidence statements”. This made me wonder whether it is just difficult for GLD and asked this question. Bootstrapping appear to be straightforward here and I guess someone already tried it, but I could not find a such paper.
2a. I had also thought that “So, on principle, they can be used everywhere a normal distribution, say, is used. “. Then I searched on google and could only find one such paper, Dean&King (2009). And in it the authors only discuss its application in SIMPLE regression! Well, the impression to me is that even the generalization to multiple regression is non-trivial…And I would like to know if there is any other research works have been done on this direction.
2b. Well, given my impression and after some thoughts, i then wondered whether it is worth doing it. In my (applied) work, most of the time I am interested more in the (functional) relationship between response and covariates(regression), or between past values and current value(time series). Much much less is paid to the error distribution. This just makes sense to me. I know we sometimes can use t distribution instead of normal to account for outliers, but I have not seen many people doing this in practice. If we then replace the error by the GLD, much much effort has to be allocated to fitting the error distribution. I agree with you that “I personally do not see any gain in using it”
I must confess that I have not heard of GLD until a few days ago when I looked for alternative distributions for copula. Therefore It is very likely I got wrong in my comments. GLD captures my attention because of its flexibility. But soon I questioned how it can really be used in practice. For example, in Tarsitano (2004), the author investigates the distribution of income data…To me, a more natural question is how income is related to other variables, say education, age and etc. Even if we are really interested in just the distribution, I guess Gaussian Mixture Model can do a quite pretty job (though it has its own problem).
Basically, I am curious why researchers have paid so much effort on this distribution. Is there any interesting applications I have missed out?
October 7, 2012 at 7:29 pm
Thanks for the details! The very short answer is no! The short answer is no, I do not think GLDs are worth investing into and no, I do not much about those distributions and their applications, as I only wrote this highly negative book review… So I would very frankly advise you not to send much time on them.
September 7, 2011 at 3:43 pm
Thanks for a very readable review. Until today I had this book on my Amazon saved list as a possible future purchase.
I would welcome any suggestions for books that cover the fitting of statistical distributions in a broader sense.
September 7, 2011 at 6:59 pm
thanks. I do not know of a book focussing on fitting all distributions, but encyclopedias like Johnson and Kotz’s obviously incluJohnson and Kotz’sde traditional estimation methods for the standard distributions.
September 7, 2011 at 3:01 pm
[…] Walking Randomly‘s report on developments in math-software in August, and two book reviews on Xi’an’s […]