 Having (rather foolishly) involved myself into providing an answer for Cross Validated: “Can the standard deviation of non-negative data exceed the mean?“, I ended up having to derive the mean of the absolute value of a Student’s variate X. (Well, not really, but then I did.) I think the following is correct:
Having (rather foolishly) involved myself into providing an answer for Cross Validated: “Can the standard deviation of non-negative data exceed the mean?“, I ended up having to derive the mean of the absolute value of a Student’s variate X. (Well, not really, but then I did.) I think the following is correct:
![\mathbb{E}[|X|]=\mu(2\text{P}_{\mu,\nu}(X>0)-1)\qquad\qquad\\ \qquad\qquad+2 f(0,\nu)\dfrac{\nu}{\nu-1}\left[1+\mu^2/\nu\right]^{-(\nu-1)/2}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%7CX%7C%5D%3D%5Cmu%282%5Ctext%7BP%7D_%7B%5Cmu%2C%5Cnu%7D%28X%3E0%29-1%29%5Cqquad%5Cqquad%5C%5C+%5Cqquad%5Cqquad%2B2+f%280%2C%5Cnu%29%5Cdfrac%7B%5Cnu%7D%7B%5Cnu-1%7D%5Cleft%5B1%2B%5Cmu%5E2%2F%5Cnu%5Cright%5D%5E%7B-%28%5Cnu-1%29%2F2%7D&bg=000000&fg=B0B0B0&s=0&c=20201002)
where 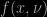 is the density of the standard Student’s distribution. (I also checked by simulation. The derivation is there. And now fully arXived. Even though it is most likely already written somewhere else. See, for instance, Psarakis and Panaretos who studied the case of the absolute centred t rv, called the folded t rv.)
is the density of the standard Student’s distribution. (I also checked by simulation. The derivation is there. And now fully arXived. Even though it is most likely already written somewhere else. See, for instance, Psarakis and Panaretos who studied the case of the absolute centred t rv, called the folded t rv.)
This entry was posted on December 1, 2011 at 12:11 am and is filed under R, Statistics, University life with tags absolute t distribution, cross validated, folded t distribution, moment derivation. You can follow any responses to this entry through the RSS 2.0 feed.
You can leave a response, or trackback from your own site.
 Having (rather foolishly) involved myself into providing an answer for Cross Validated: “Can the standard deviation of non-negative data exceed the mean?“, I ended up having to derive the mean of the absolute value of a Student’s variate X. (Well, not really, but then I did.) I think the following is correct:
Having (rather foolishly) involved myself into providing an answer for Cross Validated: “Can the standard deviation of non-negative data exceed the mean?“, I ended up having to derive the mean of the absolute value of a Student’s variate X. (Well, not really, but then I did.) I think the following is correct:
December 2, 2011 at 10:09 am
Hello,
a recent article that may interest you:
Some results on the truncated multivariate t distribution
Journal of Statistical Planning and Inference Vol 142(1) Pages 25-40
Hsiu J. Ho, Tsung-I. Lin, Hsuan-Yu Chen, Wan-Lun Wang
“We provide explicit matrix expressions for the first two moments of the truncated multivariate t (TMVT) distribution. We apply the slice sampling to generate random variates from the TMVT distribution by introducing auxiliary variables. We describe an algorithm to draw TMVT samples from a series of full conditionals that are of uniform distributions. Practical applications are given to demonstrate the effectiveness and importance of our methodology.”
December 2, 2011 at 10:16 am
Thanks a lot for the reference: the paper does not seem to have appeared yet, but I knew this derivation had to have been made somewhere sometimes!
December 2, 2011 at 10:28 am
Actually, I just found an earlier derivation by Tony O’Hagan, which dates back to…1976! And remained unpublished after being rejected by JRSS Series B.
December 1, 2011 at 9:14 pm
Often when dealing with such questions, simple discrete distributions (like the Bernoulli or sometimes adding a third point) are are a quick route to examples and counterexamples. In this case the Bernoulli with p<0.5 is sufficient to answer the question since it has standard deviation greater than its mean. So a small data set with a 1 and several 0's should be sufficient, even if the n-1 denominator is used in the sample calculation.