where did the normalising constants go?! [part 1]
 When listening this week to several talks in Banff handling large datasets or complex likelihoods by parallelisation, splitting the posterior as
When listening this week to several talks in Banff handling large datasets or complex likelihoods by parallelisation, splitting the posterior as

and handling each term of this product on a separate processor or thread as proportional to a probability density,

then producing simulations from the mi‘s and attempting at deriving simulations from the original product, I started to wonder where all those normalising constants went. What vaguely bothered me for a while, even prior to the meeting, and then unclicked thanks to Sylvia’s talk yesterday was the handling of the normalising constants ωi by those different approaches… Indeed, it seemed to me that the samples from the mi‘s should be weighted by
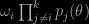
rather than just

or than the product of the other posteriors
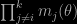
which makes or should make a significant difference. For instance, a sheer importance sampling argument for the aggregated sample exhibited those weights
![\mathbb{E}[h(\theta_i)\prod_{i=1}^k p_i(\theta_i)\big/m_i(\theta_i)]=\omega_i^{-1}\int h(\theta_i)\prod_{j}^k p_j(\theta_i)\text{d}\theta_i](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bh%28%5Ctheta_i%29%5Cprod_%7Bi%3D1%7D%5Ek+p_i%28%5Ctheta_i%29%5Cbig%2Fm_i%28%5Ctheta_i%29%5D%3D%5Comega_i%5E%7B-1%7D%5Cint+h%28%5Ctheta_i%29%5Cprod_%7Bj%7D%5Ek+p_j%28%5Ctheta_i%29%5Ctext%7Bd%7D%5Ctheta_i&bg=000000&fg=B0B0B0&s=0&c=20201002)
Hence processing the samples on an equal footing or as if the proper weight was the product of the other posteriors mj should have produced a bias in the resulting sample. This was however the approach in both Scott et al.‘s and Neiswanger et al.‘s perspectives. As well as Wang and Dunson‘s, who also started from the product of posteriors. (Normalizing constants are considered in, e.g., Theorem 1, but only for the product density and its Weierstrass convolution version.) And in Sylvia’s talk. Such a consensus of high calibre researchers cannot get it wrong! So I must have missed something: what happened is that the constants eventually did not matter, as expanded in the next post…

March 11, 2014 at 6:06 pm
[…] article was first published on Xi'an's Og » R, and kindly contributed to […]
March 11, 2014 at 5:48 am
Waiting for part 2.