Semi-automatic ABC
Last Thursday Paul Fearnhead and Dennis Prangle posted on arXiv a paper proposing an original approach to ABC. I read it rather quickly so I may miss some points in the paper but my overall feeling is of a proximity to Richard Wilkinson‘s exact ABC on an approximate target. The interesting input in the paper is that ABC is considered from a purely inferential viewpoint and calibrated for estimation purposes.
Indeed, Fearnhead and Prangle do not follow the “traditional” perspective of looking at ABC as a converging approximation to the true posterior density. As Richard Wilkinson, they take instead a randomised/noisy version of the summary statistics and derive a calibrated version of ABC, i.e. an algorithm that gives proper predictions, the jinx being that it is for the posterior given this randomised version of the summary statistics. This is therefore a tautological argument of sorts that I will call tautology #1. The interesting aspect of this switch of perspective is that the kernel K used in the acceptance probability

does not have to sound as an estimate of the true sampling density as it appears in the (randomised) pseudo-model. (Everything collapses to the true model when the bandwidth h goes to zero.) The Monte Carlo error is taken into account through the average acceptance probability, which collapses to zero when h goes to zero, therefore a suboptimal choice!
What I would call tautology #2 stems from the comparison of ABC posteriors via a loss function
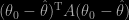
that ends up with the “best” asymptotic summary statistic being
![\mathbb{E}[\theta|y_\text{obs}].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Ctheta%7Cy_%5Ctext%7Bobs%7D%5D.&bg=000000&fg=B0B0B0&s=0&c=20201002)
This follows from the choice of the loss function rather than from an intrinsic criterion… Now, using the posterior expectation as the summary statistics does make sense! Especially when the calibration constraint implies that the ABC approximation has the same posterior mean as the true (randomised) posterior. Unfortunately it is parameterisation dependent and unlikely to be available in settings where ABC is necessary. In the semi-automatic implementation, the authors suggest to use a pilot run of ABC to approximate the above statistics. I wonder at the cost since a simulation experiment must be repeated for each simulated dataset (or sufficient statistic). The simplification in the paper follows from a linear regression on the parameters, thus linking the approach with Beaumont, Zhang and Balding (2002, Genetics).
Using the same evaluation via a posterior loss, the authors show that the “optimal” kernel is uniform over a region

where c makes a ball of volume 1. A significant remark is that the error evaluated by Fearnhead and Prangle is
![\text{tr}(A\Sigma) + h^2 \mathbb{E}_K[x^\text{T}Ax] + \dfrac{C_0}{h^d}](https://s0.wp.com/latex.php?latex=%5Ctext%7Btr%7D%28A%5CSigma%29+%2B+h%5E2+%5Cmathbb%7BE%7D_K%5Bx%5E%5Ctext%7BT%7DAx%5D+%2B+%5Cdfrac%7BC_0%7D%7Bh%5Ed%7D&bg=000000&fg=B0B0B0&s=0&c=20201002)
which means that, due to the Monte Carlo error, the “optimal” value of h is not zero but akin to a non-parametric optimal speed in 2/(2+d). There should thus be a way to link this decision-theoretic approach with the one of Ratmann et al. since the latter take h to be part of the parameter vector.

November 3, 2011 at 8:32 pm
I read this paper recently and enjoyed. As you noted, the optimal summary statistics are the (Bayesian) estimators of the parameters. I am aware that you know data cloning method suggested by Subhash Lele. Now, my question is can we use the data cloning method to obtain ML estimators of the parameters and then use them as summary statistics?
November 3, 2011 at 9:42 pm
The SAME algorithm (also know as prior feedback, data cloning, MCMC maximum likelihood, multiple imputation Metropolis EM, &tc.) can be used to represent the MLE as the limit of a sequence of Bayes estimators against replicas of the data. Now, to compute those Bayes estimators w/o the likelihood function is a bit of getting oneself in a fine pickle, isn’t it?! I simply do not see how you can implement the first step of the suggestion: computing a Bayes estimator for a k-replicate of the original data. If this is feasible, the whole Bayesian analysis of the model is feasible and the ABC shortcut is then superfluous. Please tell me which part I am missing.
November 4, 2011 at 2:44 pm
Ahh, yes. You’re right. I made a mistake in thinking. Thanks for your answer. I was thinking that I can contribute in discussing by noting about using data cloning as an alternative approach to obtain summary statistics. You brought me !
November 4, 2011 at 9:43 pm
In a formal way, the MLE or the Bayes [posterior expectation] estimator could be the “best” summary statistic, were it available. This is one of the core ideas of the paper, actually. Paul Fearnhead and Dennis Prangle use an ABC proxy to the genuine Bayes estimator as a new summary for a second ABC round.
April 18, 2011 at 12:17 am
[…] a revised version of their semi-automatic ABC paper. Compared with the earlier version commented on that post, the paper makes a better case for the ABC algorithm, when considered there from a purely […]
April 16, 2010 at 12:49 pm
Hi Christian, I’ve enjoyed reading your blog for a while so it’s nice to see your comments on our paper.
You are right that some of our results rely on quite strong assumptions. I’ll try to address your points by explaining the motivation of our approach. The starting point is our Lemma 1, which shows that (asymptotically) the Monte Carlo error increases with the number of summary statistics. So we investigate using one summary statistic for each (non-nuisance) parameter, as using any fewer intuitively leads to identifiability problems. The choice of parameter predictors as the summary statistics is now more a practical choice than a theory driven one: we can construct approximate predictors by our semi-automatic method. Our Theorem 2 shows that this is justifiable in a particular framework, namely point prediction with quadratic loss. Other loss functions lead to different optimal summary statistics which are not so easy to approximate. Noisy ABC is a method to augment the point predictions with meaningful credible intervals. Our Theorem 1 guarantees that these have some sensible coverage properties with respect to the *original* model and data.
Finally, the criticism that we assume the parameters of interest (and the parameterisation) in advance is fair. We think this covers many situations of interest and that a more exploratory setting with a large number of unknown parameters is a harder problem due to the large number of summary statistics required.
April 15, 2010 at 8:56 pm
Thanks!
April 14, 2010 at 2:51 am
I didn’t read very far into that paper (I was slacking, and I had to get back to work). It was interesting to me because I anticipate working in the near future on some models for which explicit likelihoods are not available, so I’ve been thinking about ABC a lot. One point about ABC which is not clear to me is how to choose the statistic, and this paper seemed to (?) address that very question. I can’t tell from your post whether you think this approach would be fruitful or not. Would you recommend that I try out their ideas in my own research?
April 14, 2010 at 7:37 am
Corey: I do not think the paper brings a solution in terms of the selection of statistics because one of the results in the paper is that the optimal summary statistics are the estimators of the parameters of interest. This is somehow tautological in my opinion because you have first to determine which parameters (or functions of) you are interested in.