empirical Bayes (CHANCE)
As I decided to add a vignette on empirical Bayes methods to my review of Brad Efron’s Large-scale Inference in the next issue of CHANCE [25(3)], here it is.
Empirical Bayes methods can crudely be seen as the poor man’s Bayesian analysis. They start from a Bayesian modelling, for instance the parameterised prior

and then, instead of setting α to a specific value or of assigning an hyperprior to this hyperparameter α, as in a regular or a hierarchical Bayes approach, the empirical Bayes paradigm consists in estimating α from the data. Hence the “empirical” label. The reference model used for the estimation is the integrated likelihood (or conditional marginal)
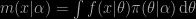
which defines a distribution density indexed by α and thus allows for the use of any statistical estimation method (moments, maximum likelihood or even Bayesian!). A classical example is provided by the normal exchangeable sample: if

then, marginally,

and μ can be estimated by the empirical average of the observations. The next step in an empirical Bayes analysis is to act as if α had not been estimated from the data and to conduct a regular Bayesian processing of the data with this estimated prior distribution. In the above normal example, this means estimating the θi‘s by

with the characteristic shrinkage (to the average) property of the resulting estimator (Efron and Morris, 1973).
“…empirical Bayes isn’t Bayes.” B. Efron (p.90)
While using Bayesian tools, this technique is outside of the Bayesian paradigm for several reasons: (a) the prior depends on the data, hence it lacks foundational justifications; (b) the prior varies with the data, hence it lacks theoretical validations like Walk’s complete class theorem; (c) the prior uses the data once, hence the posterior uses the data twice (see the vignette about this sin in the previous issue); (d) the prior relies of an estimator, whose variability is not accounted for in the subsequent analysis (Morris, 1983). The original motivation for the approach (Robbins, 1955) was more non-parametric, however it gained popularity in the 70’s and 80’s both in conjunction with the Stein effect and as a practical mean of bypassing complex Bayesian computations. As illustrated by Efron’s book, it recently met with renewed interest in connection with multiple testing.

May 1, 2012 at 5:58 am
[…] and empirical Bayes, they are related with multiple […]
April 24, 2012 at 3:28 am
Why is this “using the data twice” alleged to be problematic (on Bayesian grounds)? and how is this facet “worse” than using the data to test and alter a prior (ifit is)? What criteria are you using to judge what’s problematic? I will study this more….thanks.
April 23, 2012 at 6:11 pm
Gianola & Fernando (1986, http://www.mendeley.com/research/bayesian-methods-animal-breeding-theory/) provide a practical argument “not to reject” empirical Bayes, which is mainly that, given data enough, the results are very similar to real Bayes. This happens in most applications (BLUP) they deal with. But yes, it is poor man Bayes.
April 23, 2012 at 5:39 pm
(Sorry wasn’t logged in before.) Regarding “… the prior uses the data once, hence the posterior uses the data twice …”, they could be different data: The “data” for the prior might, for instance, be from meta-analysis and the data to hone the posterior might be from experiment. I agree the technique isn’t really Bayesian, but find that less offensive with time. I imagine there would be a hierarchical Bayes approach that takes the meta-analysis data and the experimental data as estimating two successive posteriors …
Day to day, the biggest problem I encounter in statistical practice is convincing colleagues and customers who do not know the details of methods, that the methods and their inferences are legitimate. Some of the methods are more easily understood than others, and that has become a big part of how I find I need to practice.
April 23, 2012 at 10:29 am
Thanks Christian for this very clear presentation of the empirical Bayes approach.
You mentioned different kinds of estimation methods for the hyperparameter alpha including Bayesian ones.
I recently saw a paper on genomic selection (Fang et al, 2012, Theoretical & Applied Genetics) where the authors put a prior on alpha and then estimated alpha by the mode of its posterior distribution p(alpha/data) via EM.
In that application, the authors implemented a Bayesian Lasso according to the procedure described by Park and Casella (2008) and the parameter of concern was the penalty parameter lambda. The authors put a gamma distribution G(a,b) on lambda**2 with a=0.5 and b=0. This empirical Bayes procedure worked seemingly as well as the complete one on simulated data.