 Since Bayes factor approximation is one of my areas of interest, I was intrigued by Xiao-Li Meng’s comments during my poster in Benidorm that I was using the “wrong” bridge sampling estimator when trying to bridge two models of different dimensions, based on the completion (for
Since Bayes factor approximation is one of my areas of interest, I was intrigued by Xiao-Li Meng’s comments during my poster in Benidorm that I was using the “wrong” bridge sampling estimator when trying to bridge two models of different dimensions, based on the completion (for  and
and  missing from the first model)
missing from the first model)

When revising the normal chapter of Bayesian Core, here in CiRM, I thus went back to Xiao-Li’s papers on the topic to try to fathom what the “true” bridge sampling was in that case. In Meng and Schilling (2002, JASA), I found the following indication, “when estimating the ratio of normalizing constants with different dimensions, a good strategy is to bridge each density with a good approximation of itself and then apply bridge sampling to estimate each normalizing constant separately. This is typically more effective than to artificially bridge the two original densities by augmenting the dimension of the lower one”. I was unsure of the technique this (somehow vague) indication pointed at until I understood that it meant introducing one artificial posterior distribution for each of the parameter spaces and processing each marginal likelihood as an integral ratio in itself. For instance, if  is an arbitrary normalised density on
is an arbitrary normalised density on 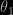 , and
, and  is an arbitrary function, we have the bridge sampling identity on
is an arbitrary function, we have the bridge sampling identity on  :
:

Therefore, the optimal choice of leads to the approximation

when 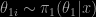 and
and  . More exactly, this approximation is replaced with an iterative version since it depends on the unknown . The choice of the density
. More exactly, this approximation is replaced with an iterative version since it depends on the unknown . The choice of the density  is obviously fundamental and it should be close to the true posterior
is obviously fundamental and it should be close to the true posterior 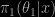 to guarantee good convergence approximation. Using a normal approximation to the posterior distribution of
to guarantee good convergence approximation. Using a normal approximation to the posterior distribution of 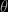 or a non-parametric approximation based on a sample from
or a non-parametric approximation based on a sample from  , or yet again an average of MCMC proposals are reasonable choices.
, or yet again an average of MCMC proposals are reasonable choices.
 The boxplot above compares this solution of Meng and Schilling (2002, JASA), called double (because two pseudo-posteriors and
The boxplot above compares this solution of Meng and Schilling (2002, JASA), called double (because two pseudo-posteriors and  have to be introduced), with Chen, Shao and Ibragim (2001) solution based on a single completion
have to be introduced), with Chen, Shao and Ibragim (2001) solution based on a single completion 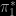 (using a normal centred at the estimate of the missing parameter, and with variance the estimate from the simulation), when testing whether or not the mean of a normal model with unknown variance is zero. The variabilities are quite comparable in this admittedly overly simple case. Overall, the performances of both extensions are obviously highly dependent on the choice of the completion factors,
(using a normal centred at the estimate of the missing parameter, and with variance the estimate from the simulation), when testing whether or not the mean of a normal model with unknown variance is zero. The variabilities are quite comparable in this admittedly overly simple case. Overall, the performances of both extensions are obviously highly dependent on the choice of the completion factors, 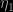 and
and 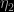 on the one hand and on the other hand, . The performances of the first solution, which bridges both models via , are bound to deteriorate as the dimension gap between those models increases. The impact of the dimension of the models is less keenly felt for the other solution, as the approximation remains local.
on the one hand and on the other hand, . The performances of the first solution, which bridges both models via , are bound to deteriorate as the dimension gap between those models increases. The impact of the dimension of the models is less keenly felt for the other solution, as the approximation remains local.
This entry was posted on July 14, 2010 at 12:00 am and is filed under Books, R, Statistics, University life with tags Bayesian Core, Benidorm, bridge sampling, CIRM, poster, Valencia 9. You can follow any responses to this entry through the RSS 2.0 feed.
You can leave a response, or trackback from your own site.
 The boxplot above compares this solution of Meng and Schilling (2002, JASA), called double (because two pseudo-posteriors
The boxplot above compares this solution of Meng and Schilling (2002, JASA), called double (because two pseudo-posteriors 
Leave a comment