Hyper-g priors
Earlier this month, Daniel Sabanés Bové and Leo Held posted a paper about g-priors on arXiv. While I glanced at it for a few minutes, I did not have the chance to get a proper look at it till last Sunday. The g-prior was first introduced by the late Arnold Zellner for (standard) linear models, but they can be extended to generalised linear models (formalised by the late John Nelder) at little cost. In Bayesian Core, Jean-Michel Marin and I do centre the prior modelling in both linear and generalised linear models around g-priors, using the naïve extension for generalised linear models,
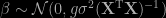
as in the linear case. Indeed, the reasonable alternative would be to include the true information matrix but since it depends on the parameter 

where W is a diagonal weight matrix and c is a family dependent scale factor evaluated at the mode 0. As in Liang et al. (2008, JASA) and most of the current literature, they also separate the intercept 
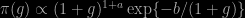
which requires the two hyper-hyper-parameters a and b to be specified.
The second part of the paper considers computational issues. It compares the ILA solution of Rue, Martino and Chopin (2009, Series B) with an MCMC solution based on an independent proposal on g resulting from linear interpolations (?). The marginal likelihoods are approximated by Chib and Jeliazkov (2001, JASA) for the MCMC part. Unsurprisingly, ILA does much better, even with a 97% acceptance rate in the MCMC algorithm.
The paper is very well-written and quite informative about the existing literature. It also uses the Pima Indian dataset (The authors even dug out a 1991 paper of mine I had completely forgotten!) I am actually thinking of using the review in our revision of Bayesian Core, even though I think we should stick to our choice of including

February 21, 2011 at 7:13 am
[…] thesis defence, her thesis being on Objective Bayes criteria for variable selection and involving hyper-g priors. The view over the Pyrénées was quite spectacular, even though there was not much snow. Further […]
February 17, 2011 at 10:25 pm
This paper has just appeared in Bayesian Analysis (volume 6, number 1, pages 1-24)
February 7, 2011 at 12:12 am
[…] Bové who gave a talk connected with the hyper-g prior paper he wrote with Leo Held (commented in an earlier post) and the duo of Janine Illian and Daniel Simpson who gave enthusiastic arguments as to why point […]
October 5, 2010 at 7:01 am
[…] Mohammed El Anbari, Jean-Michel Marin, and myself have eventually completed our paper on using hyper-g priors variable selection and regularisation in linear models . The redaction of this paper was mostly […]
September 1, 2010 at 9:05 am
Dear Christian,
thank you very much for your thoughts! I am glad that you had time to read our paper, and even write almost a review about it. I would like to add three comments:
Firstly, our remark about the improper prior on g is indeed not well formulated. Although in our paper we cannot use an improper prior on g because the intercept is not comprised in the g-prior, you actually can use an improper prior on g if you treat the intercept like the other regression coefficients, as you do in “Bayesian Core”. However, we do not want to penalise the size of the intercept so we treat it separate and assign it a flat prior. Of course, including it in the g-prior may also have advantages.
Secondly, since the prior on g is treated generally in the paper (only the density f(g) is used), we are not restricted to the use of Cui and George’s incomplete inverse-gamma prior. The latter is only included for illustration of the performance of the computational strategy in the conjugate normal case.
Thirdly, the MCMC computations are indeed based on a linear interpolation of (Laplace approximated) posterior z=log(g) ordinates to get a proposal density for z (this is the dashed line in Figure 2). We also tried some spline interpolations here, but they were unstable and did not yield higher acceptance rates.
Best regards,
Daniel
P.S.: We are also glad that you enjoyed the literature review, and we would be happy if you cite the paper in “Bayesian Core”!