Riemann, Langevin & Hamilton [reply]
Here is a (prompt!) reply from Mark Girolami corresponding to the earlier post:
In preparation for the Read Paper session next month at the RSS, our research group at CREST has collectively read the Girolami and Calderhead paper on Riemann manifold Langevin and Hamiltonian Monte Carlo methods and I hope we will again produce a joint arXiv preprint out of our comments. (The above picture is reproduced from Radford Neal’s talk at JSM 1999 in Baltimore, talk that I remember attending!) Although this only represents my preliminary/early impression on the paper, I have trouble with the Physics connection. Because it involves continuous time events that are not transcribed directly into the simulation process.
 It might be easier to look at the two attached figures rather than the isocontours in the complete phase space (q, p) of the 1-d Gaussian that is in the pic you include in your post. Both figures relate to sampling from a zero mean bivariate Gaussian with covariance matrix
It might be easier to look at the two attached figures rather than the isocontours in the complete phase space (q, p) of the 1-d Gaussian that is in the pic you include in your post. Both figures relate to sampling from a zero mean bivariate Gaussian with covariance matrix 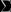

 Now lets look at the second figure. Lay aside the Physics interpretation and let’s try to adopt a geometric one in this case to see if this helps the understanding. So our task is to simulate from this bivariate Gaussian we know that the metric tensor
Now lets look at the second figure. Lay aside the Physics interpretation and let’s try to adopt a geometric one in this case to see if this helps the understanding. So our task is to simulate from this bivariate Gaussian we know that the metric tensor 
Does that alternative explanation of the deterministic proposal mechanism help?? If we accept the geometric view and wish to make proposals that follow the geodesics then integrating Hamiltons equations is just another way to solve the geodesic equations nothing more — so there is no need to appeal to the Physics interpretation at all — I am considering actually presenting the method from that perspective at the RSS meeting — thoughts on that?
Overall, trying to take advantage of second order properties of the target, just like the Langevin improvement takes advantage of the first order?is a natural idea which, when implementable, can obviously speed up convergence. This is the Langevin part, which may use a fixed metric M or a local metric defining a Riemann manifold, G(.). So far, so good, assuming the derivation of an observed or expected information G(.) is feasible up to some approximation level. The Hamiltonian part that confuses me introduces a dynamic on level sets of where p is an auxiliary vector of dimension D. Namely. while I understand the purpose of the auxiliary vector, namely to speed up the exploration of the posterior surface by taking advantage of the additional energy provided by p, I fail to understand why the fact that the discretised (Euler) approximation to Hamilton?s equations is not available in closed form is such an issue?. The fact that the (deterministic?) leapfrog integrator is not exact should not matter since this can be corrected by a Metropolis-Hastings step.
I think that I have attempted to answer your question about the auxilliary vector p. So the leapfrog integrator is NOT exact — it does not EXACTLY preserve the Hamiltonian — it is second order accurate — and the MH step corrects for the bias in the invariant measure introduced by this error.
The integrator does exactly preserve volume elements — so the determinant is not required to appear in the MH ratio — of course this requirement could be relaxed and then we would have to include the Jacobian in the MH ratio — this might be ok to compute. It is also symmetric/reversible so the effective proposal densities do not need to appear in the MH ratio – just the ratio of the joint likelihoods (q and p). In this paper I wanted to make sure everything was exact and formally correct and let further work relax these restrictions and develop more efficient numerics and / or approximations.
While the logistic example is mostly a toy problem (where importance sampling works extremely well, as shown in our survey with Jean-Michel Marin), the stochastic volatility is more challenging and the fact that the Hamiltonian scheme applies to the missing data (volatility) as well as to the three parameters of the model is quite interesting. I however wonder at the appeal of this involved scheme when considering that the full conditional of the volatility can be simulated exactly?
The LR example is indeed a toy one and it was used just to calibrate and illustrate the various methods with other well known methods — with the SV as with the log-Cox model we chose to sample from the conditionals of latent volatilities given parameters and then parameters given volatilities -—in a Gibbs style scheme — we coud also have sampled jointly or used the exact sampling from the conditional (which I must confess I had not noticed at the time) — the point being that these are illustrative of the methods proposed — I made no claim to optimality of the schemes used — they were used to illustrate the potential of the methodology.
Reversibility is a “second-order” property for MCMC algorithms. E.g., the Gibbs sampler is not reversible but does work without that property? In addition, the standard Metropolis-Hastings scheme is reversible by construction (courtesy of the detailed balance property). My point in that post (and in the incoming discussion) is that, similar to Langevin, the continuous time “analogy” may be unnecessary costly in trying to carry this analogy in discrete (algorithmic) time. We are not working in continuous time, the invariance/stability properties of the continuous time process are not carried on to the discretised version of the process, we therefore should not care about reproducing exactly the continuous time process in discrete time. For instance, when considering the Langevin diffusion, the corresponding Langevin algorithm could use another scale for the gradient than the one used for the noise, i.e.rather than the Euler discretisation. A few experiments at the time of the first edition of MCSM (Chapter 6, Section 6.5) showed that a different scale could lead to improvements.
Correct — again I wanted to be ‘purer than pure’ in the way this work was presented and whilst indeed different scaling for the drift and the diffusion terms in the Langevin scheme can work and imporve things — I felt that this is follow on work from the ideas presented — for example there are other discretisations of the Langevin SDE that may be more efficient than a simple first order Euler – which I do discuss in the final section.


October 14, 2010 at 12:15 am
[…] by presenting an overview of MCMC methods, second by giving a short discussion on the paper by Mark Girolami and Ben Calderhead. The pre-ordinary as well as the ordinary sessions were very well-attended and it is a pity that […]
October 8, 2010 at 12:06 am
[…] of the paper by Mark Girolami and Ben Calderhead at the RSS next week. Not to be confused with my comments on the […]