Number of components in a mixture
 Marin-Robert, 2007") I got a paper (unavailable online) to referee about testing for the order (i.e. the number of components) of a normal mixture. Although this is an easily spelled problem, namely estimate k in
I got a paper (unavailable online) to referee about testing for the order (i.e. the number of components) of a normal mixture. Although this is an easily spelled problem, namely estimate k in
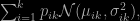
I came to the conclusion that it is a kind of ill-posed problem. Without a clear definition of what a component is, i.e. without a well-articulated prior distribution, I remain unconvinced that k can be at all estimated. Indeed, how can we distinguish between a k component mixture and a (k+1) component mixture with an extremely small (in the sense of the component weight) additional component? Solutions ending up with a convenient chi-square test thus sound unrealistic to me… I am not implying the maths are wrong in any way, simply that the meaning of the test and the nature of the null hypothesis are unclear from a practical and methodological perspective. In the case of normal (but also Laplace) mixtures, the difficulty is compounded by the fact that the likelihood function is unbounded, thus wide open to over-fitting (at least in a non-Bayesian setting). Since Ghosh and Sen (1985), authors have come up with various penalisation functions, but I remain openly atheistic about the approach! (I do not know whether or not this is related with the summer season, but I have received an unusual number of papers to referee lately, e.g., handling three papers last Friday, one on Saturday, and yet another one on Monday morning. Interestingly, about half of them are from non-statistical journals!)

December 3, 2012 at 12:21 am
[…] di due o più comunità scientifiche distinte solo sulla base delle statistiche bibliometriche è tutt’altro che banale. Infatti, dal punto di vista statistico si tratta del problema del riconoscimento automatico del […]
September 5, 2011 at 12:16 am
[…] where there is no compelling property to do so. (Which is also why as an editor/aeditor/referee, I have always been ultra-conservative vis-à-vis papers introducing new families of […]
August 7, 2011 at 12:44 am
Even Bayesian methods are open to over-fitting in cases of unknown model dimension. We observe this in Dirichlet process mixtures, despite the strong prior penalty against additional ‘components’.
For DPMs, the number of ‘components’ is the number of ‘atoms’ in the mixing distribution, or the number of distinct stochastic processes necessary to explain the data. Is this a sufficient definition?
August 6, 2011 at 4:50 pm
I’ve always wondered how this sort of thing was done. My (naive) assumption would be that you would work out the approximating properties of sums of your baseline family ( e.g. under what conditions and with what rate can a function on R be approximated by a sum of Gaussian pdfs), which should give a (tight-ish) asymptotic rate based on (I would assume) the tail properties of the pdf and some measure of ‘wriggliness’ (like total variation of the pdf), which are much more standard things to test (well, at least the first one is).
From the approximation point of view, if the procedure converges algebraically, the ratio of errors would be 1 + o(1), which would make the test impossible (the problem, as you say in the comment above, is more that order k mixtures can approximate order k+1 mixtures *extremely* well). Things are slightly better if the convergence of the scheme is geometric, but even so the best I’d expect is to be able to test if the number of components is the correct order of magnitude.
August 6, 2011 at 1:45 pm
Isn’t your comment always the case? When you do a t-test to check if the mean is 0 – couldn’t the mean be just a tiny bit above 0?
At least doing a test to see if we can reject k=1 seems plausible to me.
Since k+1 has more parameters than k, I think it is valid to ask if it is worthwhile to pay the price… is the better fit we get with k+1 Just like what you’d get if you had k, and tried to fit k+1 parameters?
But I think any kind of test like this will have the additional assumption that we have a mixture of Normals. And how woud you know if you rejected k in favor of k+1, or you rejected the assumption that you have a mixture of Normals?
August 6, 2011 at 1:51 pm
Loss (price) or prior, you have indeed to put into the problem the definition of what makes a component. Otherwise, you can add an identical component and move from k to (k+1), for the same fit. I think the problem is deeper than a mere zero mean test in that the null hypothesis (k) is reached on the (k+1) parameter space following many different paths. (I cannot track the reference at the moment, but there is an old paper on this theme…)
August 6, 2011 at 4:53 pm
I’m not sure that they do have a different number of parameters from a model point of view. I’d suspect (having put no previous thought into this) that any mixture model (fixing the family and the parameters in the mixture components) has two parameters: The number of components and the vector of weights. If you split up the weights, you run into the ‘different paths’ problem that Xi’an mentioned.