MAP estimators are not truly Bayesian estimators
This morning, I found this question from Ronald in my mailbox
“I have been reading the Bayesian Choice (2nd Edition). On page 166 you note that, for continuous parameter spaces, the MAP estimator must be defined as the limit of a sequence of estimators corresponding to a sequence of 0-1 loss functions with increasingly smaller nonzero epsilons.
This would appear to mean that the MAP estimator for continuous spaces is not Bayes-optimal, as is frequently claimed. To be Bayes-optimal, it would have to minimize the Bayes risk for a single, fixed loss function. Instead, it must be defined using an infinite sequence of loss functions.
Does there exist a formal proof of the Bayes-optimality of the continuous-space MAP estimator-meaning one that is consistent with the usual definition assuming a fixed loss function? I don’t see how there could be. If a fixed loss function actually existed, then a definition requiring a limit would be unnecessary.”
which is really making a good point against MAP estimators. In fact, I have never found MAP estimators very appealing for many reasons, one being indeed that the MAP estimator cannot correctly be expressed as the solution to a minimisation problem. I also find the pointwise nature of the estimator quite a drawback: the estimator is only associated with a local property of the posterior density, not with a global property of the posterior distribution. This is in particular striking when considering the MAP estimates for two different parameterisations. The estimates often are quite different, just due to the Jacobian in the change of parameterisation. For instance, the MAP of the usual normal mean 


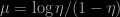
the MAP in 
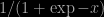


February 10, 2023 at 12:29 pm
[…] is thus significant in that the MAP of the transform is not the transform of the MAP. (There are deeper reasons for disliking MAP estimators, of […]
July 13, 2022 at 11:34 am
What if given a posterior π, we define a function on a manifold M which involves π and also another term. Then when optimization is performed on f we find that the MAP of f is the same of π ?
July 13, 2022 at 2:31 pm
Sorry, I do not understand the proposed resolution.
February 11, 2022 at 7:30 pm
Great example, thanks for sharing!
October 10, 2011 at 12:12 am
[…] there is no fixed value for the parameter!) The statement that the MAP estimator is associated with the 0-1 loss function (footnote 4, p.10) is alas found in many books and papers, thus cannot truly be blamed on the […]
April 25, 2011 at 12:14 am
[…] surprise (or maximum profile likelihood) estimators, and loss functions. I posted a while ago my perspective on MAP estimators, followed by several comments on the Bayesian nature of those estimators, hence […]