Predictive Bayes factors?!


We (as in we, the Cosmology/Statistics ANR 2005-2009 Ecosstat grant team) are currently working on a Bayesian testing paper with applications to cosmology and my colleagues showed me a paper by Roberto Trotta that I found most intriguing i its introduction of a predictive Bayes factor. A Bayes factor being a function of an observed 

- The Bayes factor associated with
- While a Bayes factor eliminates the influence of the prior probabilities of the null and of the alternative hypotheses, the predictive distribution of
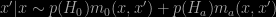
- The most natural use of the predictive distribution of
would be to look at the mass above or below 1, thus to produce a sort of Bayesian predictive p-value, falling back into old tracks.
- If the current observation
, it should be incorporated in the prior, the current posterior being then the future prior. In this case, the quantity of interest is not the predictive of

It may be that the disappearance of 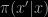
I also am puzzled by the MCMC strategy suggested in the paper in the case of embedded hypotheses. Trotta argues in §3.1 that it is sufficient to sample from the full model and to derive the Bayes factor by the Savage-Dickey representation, but this does not really agree with the approach of Chen, Shao and Ibrahim, while I think the identity (14) is missing an extra term, namely

which has the surprising feature of depending upon the value of the prior density at a specific value 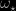


December 11, 2009 at 12:21 am
[…] The paper on evidence approximation by population Monte Carlo that I mentioned in a previous post is now arXived. (This is the second paper jointly produced by the members of the 2005-2009 ANR […]