Posterior predictive p-values and the convex order
Patrick Rubin-Delanchy and Daniel Lawson [of Warhammer fame!] recently arXived a paper we had discussed with Patrick when he visited Andrew and I last summer in Paris. The topic is the evaluation of the posterior predictive probability of a larger discrepancy between data and model

which acts like a Bayesian p-value of sorts. I discussed several times the reservations I have about this notion on this blog… Including running one experiment on the uniformity of the ppp while in Duke last year. One item of those reservations being that it evaluates the posterior probability of an event that does not exist a priori. Which is somewhat connected to the issue of using the data “twice”.
“A posterior predictive p-value has a transparent Bayesian interpretation.”
Another item that was suggested [to me] in the current paper is the difficulty in defining the posterior predictive (pp), for instance by including latent variables

which reminds me of the multiple possible avatars of the BIC criterion. The question addressed by Rubin-Delanchy and Lawson is how far from the uniform distribution stands this pp when the model is correct. The main result of their paper is that any sub-uniform distribution can be expressed as a particular posterior predictive. The authors also exhibit the distribution that achieves the bound produced by Xiao-Li Meng, Namely that
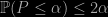
where P is the above (top) probability. (Hence it is uniform up to a factor 2!) Obviously, the proximity with the upper bound only occurs in a limited number of cases that do not validate the overall use of the ppp. But this is certainly a nice piece of theoretical work.

Leave a comment