the curious incident of the inverse of the mean
A s I figured out while working with astronomer colleagues last week, a strange if understandable difficulty proceeds from the simplest and most studied statistical model, namely the Normal model
x~N(θ,1)
Indeed, if one reparametrises this model as x~N(υ⁻¹,1) with υ>0, a single observation x brings very little information about υ! (This is not a toy problem as it corresponds to estimating distances from observations of parallaxes.) If x gets large, υ is very likely to be small, but if x is small or negative, υ is certainly large, with no power to discriminate between highly different values. For instance, Fisher’s information for this model and parametrisation is υ⁻² and thus collapses at zero.
While one can always hope for Bayesian miracles, they do not automatically occur. For instance, working with a Gamma prior Ga(3,10³) on υ [as informed by a large astronomy dataset] leads to a posterior expectation hardly impacted by the value of the observation x:
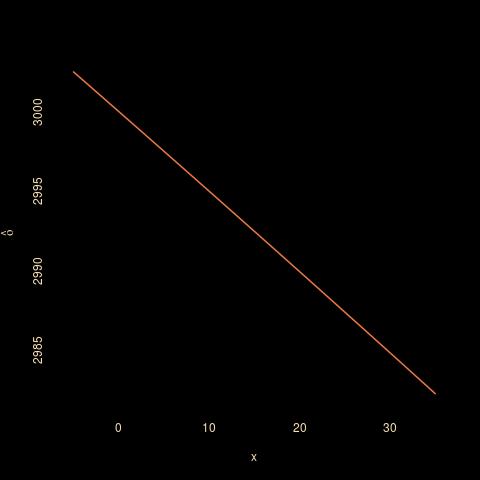 And using an alternative estimate like the harmonic posterior mean that is associated with the relative squared error loss does not see much more impact from the observation:
And using an alternative estimate like the harmonic posterior mean that is associated with the relative squared error loss does not see much more impact from the observation:
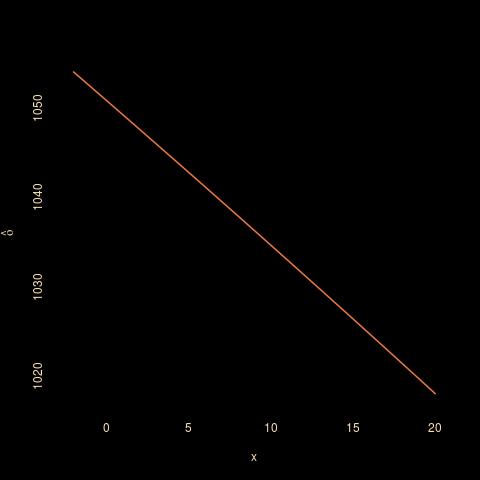 There is simply not enough information contained in one datapoint (or even several datapoints for all that matters) to infer about υ.
There is simply not enough information contained in one datapoint (or even several datapoints for all that matters) to infer about υ.

December 13, 2016 at 1:57 am
[…] on X validated about the numerical approximation of the marginal likelihood, I suggested using an harmonic mean estimate as a simple but worthless solution based on an MCMC posterior sample. This was on a toy example […]
July 15, 2016 at 1:42 am
Bayesian miracles never occur. Or, to put it differently (and biblically), faith without works is dead.
That parameterisation (and parameterisations like it) only occur when you don’t consider how a single data point adds information to the inference.
It’s a good lesson to learn (and a very nice example!), but not a surprise.