what makes variables randoms [book review]
 When the goal of a book is to make measure theoretic probability available to applied researchers for conducting their research, I cannot but applaud! Peter Veazie’s goal of writing “a brief text that provides a basic conceptual introduction to measure theory” (p.4) is hence most commendable. Before reading What makes variables random, I was uncertain how this could be achieved with a limited calculus background, given the difficulties met by our third year maths students. After reading the book, I am even less certain this is feasible!
When the goal of a book is to make measure theoretic probability available to applied researchers for conducting their research, I cannot but applaud! Peter Veazie’s goal of writing “a brief text that provides a basic conceptual introduction to measure theory” (p.4) is hence most commendable. Before reading What makes variables random, I was uncertain how this could be achieved with a limited calculus background, given the difficulties met by our third year maths students. After reading the book, I am even less certain this is feasible!
“…it is the data generating process that makes the variables random and not the data.”
Chapter 2 is about basic notions of set theory. Chapter 3 defines measurable sets and measurable functions and integrals against a given measure μ as
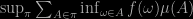
which I find particularly unnatural compared with the definition through simple functions (esp. because it does not tell how to handle 0x∞). The ensuing discussion shows the limitation of the exercise in that the definition is only explained for finite sets (since the notion of a partition achieving the supremum on page 29 is otherwise meaningless). A generic problem with the book, in that most examples in the probability section relate to discrete settings (see the discussion of the power set p.66). I also did not see a justification as to why measurable functions enjoy well-defined integrals in the above sense. All in all, to see less than ten pages allocated to measure theory per se is rather staggering! For instance,

does not appear to be defined at all.
“…the mathematical probability theory underlying our analyses is just mathematics…”
Chapter 4 moves to probability measures. It distinguishes between objective (or frequentist) and subjective measures, which is of course open to diverse interpretations. And the definition of a conditional measure is the traditional one, conditional on a set rather than on a σ-algebra. Surprisingly as this is in my opinion one major reason for using measures in probability theory. And avoids unpleasant issues such as Bertrand’s paradox. While random variables are defined in the standard sense of real valued measurable functions, I did not see a definition of a continuous random variables or of the Lebesgue measure. And there are only a few lines (p.48) about the notion of expectation, which is so central to measure-theoretic probability as to provide a way of entry into measure theory! Progressing further, the σ-algebra induced by a random variable is defined as a partition (p.52), a particularly obscure notion for continuous rv’s. When the conditional density of one random variable given the realisation of another is finally introduced (p.63), as an expectation reconciling with the set-wise definition of conditional probabilities, it is in a fairly convoluted way that I fear will scare newcomers out of their wit. Since it relies on a sequence of nested sets with positive measure, implying an underlying topology and the like, which somewhat shows the impossibility of the overall task…
“In the Bayesian analysis, the likelihood provides meaning to the posterior.”
Statistics is hurriedly introduced in a short section at the end of Chapter 4, assuming the notion of likelihood is already known by the readers. But nitpicking (p.65) at the representation of the terms in the log-likelihood as depending on an unspecified parameter value θ [not to be confused with the data-generating value of θ, which does not appear clearly in this section]. Section that manages to include arcane remarks distinguishing maximum likelihood estimation from Bayesian analysis, all this within a page! (Nowhere is the Bayesian perspective clearly defined.)
“We should no more perform an analysis clustered by state than we would cluster by age, income, or other random variable.”
The last part of the book is about probabilistic models, drawing a distinction between data generating process models and data models (p.89), by which the author means the hypothesised probabilistic model versus the empirical or bootstrap distribution. An interesting way to relate to the main thread, except that the convergence of the data distribution to the data generating process model cannot be established at this level. And hence that the very nature of bootstrap may be lost on the reader. A second and final chapter covers some common or vexing problems and the author’s approach to them. Revolving around standard errors, fixed and random effects. The distinction between standard deviation (“a mathematical property of a probability distribution”) and standard error (“representation of variation due to a data generating process”) that is followed for several pages seems to boil down to a possible (and likely) model mis-specification. The chapter also contains an extensive discussion of notations, like indexes (or indicators), which seems a strange focus esp. at this location in the book. Over 15 pages! (Furthermore, I find quite confusing that a set of indices is denoted there by the double barred I, usually employed for the indicator function.)
“…the reader will probably observe the conspicuous absence of a time-honoured topic in calculus courses, the “Riemann integral”… Only the stubborn conservatism of academic tradition could freeze it into a regular part of the curriculum, long after it had outlived its historical importance.” Jean Dieudonné, Foundations of Modern Analysis
In conclusion, I do not see the point of this book, from its insistence on measure theory that never concretises for lack of mathematical material to an absence of convincing examples as to why this is useful for the applied researcher, to the intended audience which is expected to already quite a lot about probability and statistics, to a final meandering around linear models that seems at odds with the remainder of What makes variables random, without providing an answer to this question. Or to the more relevant one of why Lebesgue integration is preferable to Riemann integration. (Not that there does not exist convincing replies to this question!)

December 7, 2017 at 11:00 pm
Having both read this book and known the man who wrote it for 17 years now, I would like to respectfully disagree with your review. It is not in the content of your critique that I disagree, as most of it is logically and mathematically sound based on your assumptions. My disagreement stems from the point of view the critique is written from. I am a perfect example of the target audience of this book (hence my reading of it before it was officially published), and I found that it clarified my understanding of both measure theory and probability models to an order of magnitude higher than before reading this book. As you are a statistics professor, it is understandable that you would take issue with the manner in which certain issues are introduced, as would any teacher with their own particular teaching style. At the level that this book is attempting to reach, the usage of discrete examples and models through much of the book is perfect for those with a limited calculus background. Continuous variables would require more extensive calculus, and it is not unreasonable that an applied researcher with limited calculus knowledge would rarely encounter continuous variables. The definitions discussed in your criticism of chapter 3 also make sense from the perspective of an applied researcher. I have personally rarely encountered the necessity for infinite sets in my work. Finite sets are much more applicable to real world research, which is the obvious focus of this book (considering its target audience of “applied researchers”). In fact, much of the criticism you level at this book can be boiled down to looking at this from a pure math perspective, as opposed to applied research. To conclude, I would like to state that you would be surprised at the lack of understanding of many concepts in this book by applied researchers. Myself and my peers have become increasingly reliant on allowing computers to “plug and chug” our data into models, without actually grasping why these measures work the way they do. This book helps explain that in the context of the work that we do.
December 8, 2017 at 10:11 am
Thank you very much for checking my review and for taking time to write your comments, most welcomed! My main criticism is not a matter of teaching style, but of a mathematical nature, though, as measure theory is only relevant in continuous settings, which is why the Lebesgue integral differs from the Riemann integral. In discrete finite settings, one never uses measure-theoretic concepts. Hence my feeling that the book does not meet its goal, by stopping just at the level when measure becomes important…