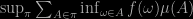On the plane back from Vancouver, I read Bertrand’s Paradox Resolution and Its Implications for the Bing–Fisher Problem by Richard A. Chechile [who had pointed out his paper to me] In this paper, Chechile considers the Bayesian connections/sequences of Betrand’s paradox, as he sees it Bertrand’s different solutions/paradox to be
“designed to illustrate his dissatisfaction with the Bayes and Laplace use of a probability distribution to represent an unknown parameter that can have any continuous value”
and proposes to “resolve” this paradox, which imho is neither a paradox nor in need of a resolution!, as I see it more like a reflection on the importance of sigma algebras and measure theory. The uniform distribution (behind the “random” chord) is not a uniquely specified concept, just like the maximum entropy distribution is relative to the dominating measure. When arguing that
“Such a definition [based on any possible distribution of a stochastic chord] would yield a random variable, but this weak sense of the word random is not satisfactory, because there is an infinite number of stochastic processes that can be defined to yield a probability distribution of chord lengths.”
the author is simply restating that infinite collection of dominating measures. But imho he is somewhat missing this point when defining Shannon`s entropy by resorting to a discrete version. And when adopting a uniform measure on the chord as a reference (Section 3.2, on The Importance of a Dominant Metric Representation). While the probability P(L>1) is invariant under any increasing transform of L (and 1)… This amounts to arguing for a favourite parameterisation in constructing a reference prior (Section 4, where Jeffreys prior is also dismissed for not being at maximum entropy). The ensuing discussion as to why the three solutions of Bertrand’s are not valid (Section 2.2) is thus most curious to me since they all are implementable/practical ways of producing stochastic chords. I find it rather amusing that one returns to the quest for the ideal priori distribution Bayesians were so fiercely debating at the turn of the previous century. And non-Bayesians were all too happy to exploit when arguing against this approach.