MAP estimators (cont’d)
In connection with Anthony’s comments, here are the details for the normal example. I am using a flat prior on 




![\pi(\eta|x) = \exp[ -(\text{logit}(\eta)-x)^2/2 ] / \sqrt{2\pi} \eta (1-\eta)](https://s0.wp.com/latex.php?latex=%5Cpi%28%5Ceta%7Cx%29+%3D+%5Cexp%5B+-%28%5Ctext%7Blogit%7D%28%5Ceta%29-x%29%5E2%2F2+%5D+%2F+%5Csqrt%7B2%5Cpi%7D+%5Ceta+%281-%5Ceta%29&bg=000000&fg=ffffff&s=0&c=20201002)
and the MAP in
f=function(x,mea) dnorm(log(x/(1-x)),mean=mea)/(x*(1-x)) g=function(x){ a=optimise(f,int=c(0,1),maximum=TRUE,mea=x)$max;log(a/(1-a))} plot(seq(0,4,.01),apply(as.matrix(seq(0,4,.01)),1,g),type="l",col="sienna",lwd=2) abline(a=0,b=1,col="tomato2",lwd=2)
shows the divergence between the MAP estimator 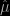
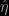

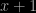
An example I like very much in The Bayesian Choice is Example 4.1.2, when observing 


The dependence of the MAP estimator on the dominating measure is also studied in a BA paper by Pierre Druihlet and Jean-Michel Marin, who propose a solution that relies on Jeffreys’ prior as the reference measure.

April 25, 2011 at 12:14 am
[…] estimators, and loss functions. I posted a while ago my perspective on MAP estimators, followed by several comments on the Bayesian nature of those estimators, hence will not reproduce them here, but the core of the […]
September 13, 2009 at 10:32 pm
From Jerymn (2005) [http://dx.doi.org/10.1214/009053604000001273] the answer to my question is apparently that this is indeed the unique way to obtain parametrization-invariant MAP estimates.
September 13, 2009 at 5:31 pm
Druilhet and Marin’s paper is very illuminating. Does this imply that whenever one wants a MAP estimate, they should compute it wrt a (Bernardo) reference prior dominating measure? I’m pretty sure this is not prevalent in machine learning, a literature in which MAP estimation is used fairly often. I think parametrization invariance is pretty crucial for meaningful inference. Do there exist other (non-trivial and statistically reasonable) candidates for dominating measures that will give identical MAP estimates under reparametrization?
September 13, 2009 at 5:42 pm
Formally, you could define an arbitrary prior/reference measure on an arbitrary parameterisation and then impose invariance by reparameterisation. Of course this would be mostly meaningless…