Riemann, Langevin & Hamilton
 Radford Neal, 1999") In preparation for the Read Paper session next month at the RSS, our research group at CREST has collectively read the Girolami and Calderhead paper on Riemann manifold Langevin and Hamiltonian Monte Carlo methods and I hope we will again produce a joint arXiv preprint out of our comments. (The above picture is reproduced from Radford Neal’s talk at JSM 1999 in Baltimore, talk that I remember attending…) Although this only represents my preliminary/early impression on the paper, I have trouble with the Physics connection. Because it involves continuous time events that are not transcribed directly into the simulation process.
In preparation for the Read Paper session next month at the RSS, our research group at CREST has collectively read the Girolami and Calderhead paper on Riemann manifold Langevin and Hamiltonian Monte Carlo methods and I hope we will again produce a joint arXiv preprint out of our comments. (The above picture is reproduced from Radford Neal’s talk at JSM 1999 in Baltimore, talk that I remember attending…) Although this only represents my preliminary/early impression on the paper, I have trouble with the Physics connection. Because it involves continuous time events that are not transcribed directly into the simulation process.
Overall, trying to take advantage of second order properties of the target—just like the Langevin improvement takes advantage of the first order—is a natural idea which, when implementable, can obviously speed up convergence. This is the Langevin part, which may use a fixed metric M or a local metric defining a Riemann manifold, G(θ). So far, so good, assuming the derivation of an observed or expected information G(θ) is feasible up to some approximation level. The Hamiltonian part that confuses me introduces a dynamic on level sets of
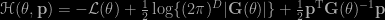
where p is an auxiliary vector of dimension D. Namely,

While I understand the purpose of the auxiliary vector, namely to speed up the exploration of the posterior surface by taking advantage of the additional energy provided by p, I fail to understand why the fact that the discretised (Euler) approximation to Hamilton’s equations is not available in closed form is such an issue…. The fact that the (deterministic?) leapfrog integrator is not exact should not matter since this can be corrected by a Metropolis-Hastings step.
While the logistic example is mostly a toy problem (where importance sampling works extremely well, as shown in our survey with Jean-Michel Marin), the stochastic volatility is more challenging and the fact that the Hamiltonian scheme applies to the missing data (volatility) as well as to the three parameters of the model is quite interesting. I however wonder at the appeal of this involved scheme when considering that the full conditional of the volatility can be simulated exactly…

December 5, 2011 at 12:12 am
[…] problems, introducing regular versions of the algorithm as well the Langevin extension (but not the Hamiltonian) and Green’s (1995) reversible jump algorithm, before spending the third half of the chapter […]
November 24, 2011 at 12:11 am
[…] Setting Path Lengths in Hamiltonian Monte Carlo” and developing an improvement on the Hamiltonian Monte Carlo algorithm called NUTS (!). Here is the […]
August 3, 2011 at 11:50 am
[…] which involved hybrid Monte Carlo on complex likelihoods. This was quite interesting, as hybrid Monte Carlo is indeed the solution to diminish the number of likelihood evaluations, since it moves along […]
October 29, 2010 at 6:10 am
[…] and Jean-Michel Marin, we submitted three discussions, running along the arguments made in this earlier post. They are available […]
October 8, 2010 at 12:06 am
[…] Those are the slides for the (basic) introduction of the paper by Mark Girolami and Ben Calderhead at the RSS next week. Not to be confused with my comments on the […]
September 27, 2010 at 3:53 pm
[…] Xi'an's Og an attempt at bloggin, from scratch… « Riemann, Langevin & Hamilton […]
September 27, 2010 at 7:12 am
OK, I get your point, and will reach for my copy of MCSM as soon as I arrive back in my office tomorrow morning. Indeed, would be interesting to think of inherently discrete-time similar algorithms — especially as, on the toy example that Luke Bornn and I have run for our comment, we have stumbled upon the typical chaotic pattern of the fixed-point iterations used to solve the steps of the generalized leapfrog [although that’s no big deal, as a/ the trajectory get rejected anyway, b/ other root-finding algorithm can be used in this context].
September 27, 2010 at 4:50 am
Actually, it would be interesting to see how much the acceptance rate would drop when using a voluntarily flawed closed-form integrator, and if the increased speed would compensate for it.
Besides, wouldn’t this integrator still have to be reversible ? Or would the Metropolis-Hastings rejection correct this too ? [the potential lack of “volume-preservation” (i.e. Jacobian \neq 1) is not a problem, as we can introduce the Jacobian in the MH ratio [assuming it can be computed !], similar to what’s done in Reversible Jump if I remember well].
The original version of the paper ( http://arxiv.org/pdf/0907.1100v1 ) had a (now removed) additional author and a (now removed) closed-form integrator. Although this integrator has been pulled because it was flawed (scientific grapevine hearsay, and I don’t know what the flaw was — nor did I check it, I openly confess), we can check the simulation results it gave, on the same examples, for an indication of the performance drop — except if the flaw was a Jacobian issue, which of course would have flawed the MH ratio.
I’ll call Mark’s attention on this thread — but he might want to save his comments for the discussion answers.
September 27, 2010 at 6:57 am
Reversibility is a “second-order” property for MCMC algorithms. E.g., the Gibbs sampler is not reversible but does work without that property… In addition, the standard Metropolis-Hastings scheme is reversible by construction (courtesy of the detailed balance property). My point in that post (and in the incoming discussion) is that, similar to Langevin, the continuous time “analogy” may be unnecessary costly in trying to carry this analogy in discrete (algorithmic) time… We are not working in continuous time, the invariance/stability properties of the continuous time process are not carried on to the discretised version of the process, we therefore should not care about reproducing exactly the continuous time process in discrete time. For instance, when considering the Langevin diffusion, the corresponding Langevin algorithm could use another scale for the gradient than the one used for the noise, i.e.
rather than the Euler discretisation
A few experiments at the time of the first edition of MCSM (Chapter 6, Section 6.5) showed that a different scale could lead to improvements.