control functionals for Monte Carlo integration
![]() This new arXival by Chris Oates, Mark Girolami, and Nicolas Chopin (warning: they all are colleagues & friends of mine!, at least until they read those comments…) is a variation on control variates, but with a surprising twist namely that the inclusion of a control variate functional may produce a sub-root-n (i.e., faster than √n) convergence rate in the resulting estimator. Surprising as I did not know one could get to sub-root-n rates..! Now I had forgotten that Anne Philippe and I used the score in an earlier paper of ours, as a control variate for Riemann sum approximations, with faster convergence rates, but this is indeed a new twist, in particular because it produces an unbiased estimator.
This new arXival by Chris Oates, Mark Girolami, and Nicolas Chopin (warning: they all are colleagues & friends of mine!, at least until they read those comments…) is a variation on control variates, but with a surprising twist namely that the inclusion of a control variate functional may produce a sub-root-n (i.e., faster than √n) convergence rate in the resulting estimator. Surprising as I did not know one could get to sub-root-n rates..! Now I had forgotten that Anne Philippe and I used the score in an earlier paper of ours, as a control variate for Riemann sum approximations, with faster convergence rates, but this is indeed a new twist, in particular because it produces an unbiased estimator.
The control variate writes
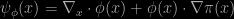
where π is the target density and φ is a free function to be optimised. (Under the constraint that πφ is integrable. Then the expectation of ψφ is indeed zero.) The “explanation” for the sub-root-n behaviour is that ψφ is chosen as an L2 regression. When looking at the sub-root-n convergence proof, the explanation is more of a Rao-Blackwellisation type, assuming a first level convergent (or presistent) approximation to the integrand [of the above form ψφ can be found. The optimal φ is the solution of a differential equation that needs estimating and the paper concentrates on approximating strategies. This connects with Antonietta Mira’s zero variance control variates, but in a non-parametric manner, adopting a Gaussian process as the prior on the unknown φ. And this is where the huge innovation in the paper resides, I think, i.e. in assuming a Gaussian process prior on the control functional and in managing to preserve unbiasedness. As in many of its implementations, modelling by Gaussian processes offers nice features, like ψφ being itself a Gaussian process. Except that it cannot be shown to lead to presistency on a theoretical basis. Even though it appears to hold in the examples of the paper. Apart from this theoretical difficulty, the potential hardship with the method seems to be in the implementation, as there are several parameters and functionals to be calibrated, hence calling for cross-validation which may often be time-consuming. The gains are humongous, so the method should be adopted whenever the added cost in implementing it is reasonable, cost which evaluation is not clearly provided by the paper. In the toy Gaussian example where everything can be computed, I am surprised at the relatively poor performance of a Riemann sum approximation to the integral, wondering at the level of quadrature involved therein. The paper also interestingly connects with O’Hagan’s (1991) Bayes-Hermite [polynomials] quadrature and quasi-Monte Carlo [obviously!].

Leave a comment