
Archive for simulation
Xuriouser & Xuriouser
Posted in Books, Statistics with tags accept, Bayesian computational methods, cross validated, Metropolis-Hastings algorithms, Monte Carlo Statistical Methods, normalising constant, principle of proportionality, screenshot, simulation on May 8, 2024 by xi'an
simulation as optimization [by kernel gradient descent]
Posted in Books, pictures, Statistics, University life with tags ABC, biking, Charles Stein, CREST, diffusions, discrepancies, Edo, Gare de Lyon, gradient descent, Hiroshige, INRIA, kernel Stein discrepancy descent, Kullback-Leibler divergence, maximum mean discrepancy, MCMC, Mokaplan, mollified discrepancy, New York city, One Hundred Famous Views of Edo, optimal transport, optimisation, Paris, simulation, SMC, Stein kernel on April 13, 2024 by xi'an Yesterday, which proved an unseasonal bright, warm, day, I biked (with a new wheel!) to the east of Paris—in the Gare de Lyon district where I lived for three years in the 1980’s—to attend a Mokaplan seminar at INRIA Paris, where Anna Korba (CREST, to which I am also affiliated) talked about sampling through optimization of discrepancies.
Yesterday, which proved an unseasonal bright, warm, day, I biked (with a new wheel!) to the east of Paris—in the Gare de Lyon district where I lived for three years in the 1980’s—to attend a Mokaplan seminar at INRIA Paris, where Anna Korba (CREST, to which I am also affiliated) talked about sampling through optimization of discrepancies.
 This proved a most formative hour as I had not seen this perspective earlier (or possibly had forgotten about it). Except through some of the talks at the Flatiron Institute on Transport, Diffusions, and Sampling last year. Incl. Marilou Gabrié’s and Arnaud Doucet’s.
This proved a most formative hour as I had not seen this perspective earlier (or possibly had forgotten about it). Except through some of the talks at the Flatiron Institute on Transport, Diffusions, and Sampling last year. Incl. Marilou Gabrié’s and Arnaud Doucet’s.
 The concept behind remains attractive to me, at least conceptually, since it consists in approximating the target distribution, known up to a constant (a setting I have always felt standard simulation techniques was not exploiting to the maximum) or through a sample (a setting less convincing since the sample from the target is already there), via a sequence of (particle approximated) distributions when using the discrepancy between the current distribution and the target or gradient thereof to move the particles. (With no randomness in the Kernel Stein Discrepancy Descent algorithm.)
The concept behind remains attractive to me, at least conceptually, since it consists in approximating the target distribution, known up to a constant (a setting I have always felt standard simulation techniques was not exploiting to the maximum) or through a sample (a setting less convincing since the sample from the target is already there), via a sequence of (particle approximated) distributions when using the discrepancy between the current distribution and the target or gradient thereof to move the particles. (With no randomness in the Kernel Stein Discrepancy Descent algorithm.)
 Ana Korba spoke about practically running the algorithm, as well as about convexity properties and some convergence results (with mixed performances for the Stein kernel, as opposed to SVGD). I remain definitely curious about the method like the (ergodic) distribution of the endpoints, the actual gain against an MCMC sample when accounting for computing time, the improvement above the empirical distribution when using a sample from π and its ecdf as the substitute for π, and the meaning of an error estimation in this context.
Ana Korba spoke about practically running the algorithm, as well as about convexity properties and some convergence results (with mixed performances for the Stein kernel, as opposed to SVGD). I remain definitely curious about the method like the (ergodic) distribution of the endpoints, the actual gain against an MCMC sample when accounting for computing time, the improvement above the empirical distribution when using a sample from π and its ecdf as the substitute for π, and the meaning of an error estimation in this context.
“exponential convergence (of the KL) for the SVGD gradient flow does not hold whenever π has exponential tails and the derivatives of ∇ log π and k grow at most at a polynomial rate”

mostly MC [April]
Posted in Books, Kids, Statistics, University life with tags #ERCSyG, Bayesian computational methods, Bayesian inference, denoising, generative models, Institut PR[AI]RIE, JMLR, machine learning, Markov chain Monte Carlo, MCMC, Monte Carlo methods, Monte Carlo Statistical Methods, mostly Monte Carlo seminar, multimodal target, Ocean, optimization, Paris, PariSanté campus, PSC, sampling, score-based generative models, seminar, simulation, stochastic diffusions, stochastic localization, variational autoencoders on April 5, 2024 by xi'an
on the edge and online!
Posted in Books, Statistics, Travel, University life with tags advanced Monte Carlo methods, antithetic sampling, convergence, efficient importance sampling, MCMC, Monte Carlo Statistical Methods, open access, pseudo-random generators, simulation, Statistical Science, Università Ca' Foscari Venezia, Venice on March 11, 2024 by xi'an 115 - 136, February 2024, DOI: 10.1214/23-STS888, with open access")
simulating signed mixtures
Posted in Books, pictures, R, Statistics, University life with tags accept-reject algorithm, arXiv, fundamental lemma of simulation, HAL, inverse cdf, mixtures of distributions, Monte Carlo Statistical Methods, pseudo-random generator, simulation on February 2, 2024 by xi'an
While simulating from a mixture of standard densities is relatively straightforward, when the component densities are easily simulated, to the point that many simulation methods exploit an intermediary mixture construction to speed up the production of pseudo-random samples from more challenging distributions (see Devroye, 1986), things get surprisingly more complicated when the mixture weights can take negative values. For instance, the naïve solution consisting in first simulating from the associated mixture of positive weight components
and then using an accept-reject step may prove highly inefficient since the overall probability of acceptance
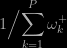
is the inverse of the sum of the positive weights and hence can be arbitrarily close to zero. The intuition for such inefficiency is that simulating from the positive weight components need not produce values within regions of high probability for the actual distribution

since its negative weight components may remove most of the mass under the positive weight components. In other words, the negative weight components do not have a natural latent variable interpretation and the resulting mixture can be anything, as the above graph testifies.
 Julien Stoehr (Paris Dauphine) and I started investigating this interesting challenge when the Master students who had been exposed to said challenge could not dent it in any meaningful way. We have now arXived a specific algorithm that proves superior to the naïve accept-reject algorithm, but also to the numerical cdf inversion (which happens to be available in this setting). Compared with the naïve version, we construct an alternative accept-reject scheme based on pairing positive and negative components as well as possible, partitioning the real line, and finding tighter upper and lower bounds on positive and negative components, respectively, towards yielding a higher acceptance rate on average. Designing a random generator of signed mixtures with enough variability and representativity proved a challenge in itself!
Julien Stoehr (Paris Dauphine) and I started investigating this interesting challenge when the Master students who had been exposed to said challenge could not dent it in any meaningful way. We have now arXived a specific algorithm that proves superior to the naïve accept-reject algorithm, but also to the numerical cdf inversion (which happens to be available in this setting). Compared with the naïve version, we construct an alternative accept-reject scheme based on pairing positive and negative components as well as possible, partitioning the real line, and finding tighter upper and lower bounds on positive and negative components, respectively, towards yielding a higher acceptance rate on average. Designing a random generator of signed mixtures with enough variability and representativity proved a challenge in itself!
