Posterior likelihood
 At the Edinburgh mixture estimation workshop, Murray Aitkin presented his proposal to compare models via the posterior distribution of the likelihood ratio.
At the Edinburgh mixture estimation workshop, Murray Aitkin presented his proposal to compare models via the posterior distribution of the likelihood ratio.
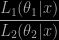
As already commented in a post last July, the positive aspect of looking at this quantity rather than at the Bayes factor is that the priors are then allowed to be improper if one simulates from the posteriors for each model, as in Aitkin et al. (2007). My overall feeling has not changed though, namely the ratio should be instead considered under the joint posterior of 

instead of the product of both posteriors. This of course makes a whole difference, as shown on the next R graph that compares the distribution of the likelihood ratio under the true posterior and under the product of posteriors (when comparing a Poisson model against a negative binomial with 
successes trials, when 
 Obviously, this joint perspective also cancels the appeal of the approach under improper priors.
Obviously, this joint perspective also cancels the appeal of the approach under improper priors.

November 16, 2010 at 12:06 am
[…] to use in parallel simulations from the posteriors under each model. As discussed in an earlier post, this is not possible. The book suggests to run model comparison via the distribution of the […]
March 23, 2010 at 1:50 am
[…] Posterior likelihood « Xi'an's Og […]