a general framework for updating belief functions
Pier Giovanni Bissiri, Chris Holmes and Stephen Walker have recently arXived the paper related to Sephen’s talk in London for Bayes 250. When I heard the talk (of which some slides are included below), my interest was aroused by the facts that (a) the approach they investigated could start from a statistics, rather than from a full model, with obvious implications for ABC, & (b) the starting point could be the dual to the prior x likelihood pair, namely the loss function. I thus read the paper with this in mind. (And rather quickly, which may mean I skipped important aspects. For instance, I did not get into Section 4 to any depth. Disclaimer: I wasn’t nor is a referee for this paper!)
The core idea is to stick to a Bayesian (hardcore?) line when missing the full model, i.e. the likelihood of the data, but wishing to infer about a well-defined parameter like the median of the observations. This parameter is model-free in that some degree of prior information is available in the form of a prior distribution. (This is thus the dual of frequentist inference: instead of a likelihood w/o a prior, they have a prior w/o a likelihood!) The approach in the paper is to define a “posterior” by using a functional type of loss function that balances fidelity to prior and fidelity to data. The prior part (of the loss) ends up with a Kullback-Leibler loss, while the data part (of the loss) is an expected loss wrt to l(THETASoEUR,x), ending up with the definition of a “posterior” that is
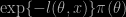
the loss thus playing the role of the log-likelihood.
I like very much the problematic developed in the paper, as I think it is connected with the real world and the complex modelling issues we face nowadays. I also like the insistence on coherence like the updating principle when switching former posterior for new prior (a point sorely missed in this book!) The distinction between M-closed M-open, and M-free scenarios is worth mentioning, if only as an entry to the Bayesian processing of pseudo-likelihood and proxy models. I am however not entirely convinced by the solution presented therein, in that it involves a rather large degree of arbitrariness. In other words, while I agree on using the loss function as a pivot for defining the pseudo-posterior, I am reluctant to put the same faith in the loss as in the log-likelihood (maybe a frequentist atavistic gene somewhere…) In particular, I think some of the choices are either hard or impossible to make and remain unprincipled (despite a call to the LP on page 7). I also consider the M-open case as remaining unsolved as finding a convergent assessment about the pseudo-true parameter brings little information about the real parameter and the lack of fit of the superimposed model. Given my great expectations, I ended up being disappointed by the M-free case: there is no optimal choice for the substitute to the loss function that sounds very much like a pseudo-likelihood (or log thereof). (I thought the talk was more conclusive about this, I presumably missed a slide there!) Another great expectation was to read about the proper scaling of the loss function (since L and wL are difficult to separate, except for monetary losses). The authors propose a “correct” scaling based on balancing both faithfulness for a single observation, but this is not a completely tight argument (dependence on parametrisation and prior, notion of a single observation, &tc.)
The illustration section contains two examples, one of which is a full-size or at least challenging genetic data analysis. The loss function is based on a logistic pseudo-likelihood and it provides results where the Bayes factor is in agreement with a likelihood ratio test using Cox’ proportional hazard model. The issue about keeping the baseline function as unkown reminded me of the Robbins-Wasserman paradox Jamie discussed in Varanasi. The second example offers a nice feature of putting uncertainties onto box-plots, although I cannot trust very much the 95% of the credibles sets. (And I do not understand why a unique loss would come to be associated with the median parameter, see p.25.)
Watch out: Tomorrow’s post contains a reply from the authors!

Leave a comment