scaling the Gibbs posterior credible regions
“The challenge in implementation of the Gibbs posterior is that it depends on an unspecified scale (or inverse temperature) parameter.”
A new paper by Nick Syring and Ryan Martin was arXived today on the same topic as the one I discussed last January. The setting is the same as with empirical likelihood, namely that the distribution of the data is not specified, while parameters of interest are defined via moments or, more generally, a minimising a loss function. A pseudo-likelihood can then be constructed as a substitute to the likelihood, in the spirit of Bissiri et al. (2013). It is called a “Gibbs posterior” distribution in this paper. So the “Gibbs” in the title has no link with the “Gibbs” in Gibbs sampler, since inference is conducted with respect to this pseudo-posterior. Somewhat logically (!), as n grows to infinity, the pseudo- posterior concentrates upon the pseudo-true value of θ minimising the expected loss, hence asymptotically resembles to the M-estimator associated with this criterion. As I pointed out in the discussion of Bissiri et al. (2013), one major hurdle when turning a loss into a log-likelihood is that it is at best defined up to a scale factor ω. The authors choose ω so that the Gibbs posterior
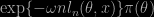
is well-calibrated. Where ln is the empirical averaged loss. So the Gibbs posterior is part of the matching prior collection. In practice the authors calibrate ω by a stochastic optimisation iterative process, with bootstrap on the side to evaluate coverage. They briefly consider empirical likelihood as an alternative, on a median regression example, where they show that their “Gibbs confidence intervals (…) are clearly the best” (p.12). Apart from the relevance of being “well-calibrated”, and the asymptotic nature of the results. and the dependence on the parameterisation via the loss function, one may also question the possibility of using this approach in large dimensional cases where all of or none of the parameters are of interest.

Leave a comment