delayed acceptance with prefetching
In a somewhat desperate rush (started upon my return from Iceland and terminated on my return from Edinburgh), Marco Banterle, Clara Grazian and I managed to complete and submit our paper by last Friday evening… It is now arXived as well. The full title of the paper is Accelerating Metropolis-Hastings algorithms: Delayed acceptance with prefetching and the idea behind the generic acceleration is (a) to divide the acceptance step into parts, towards a major reduction in computing time that outranks the corresponding reduction in acceptance probability and (b) to exploit this division to build a dynamic prefetching algorithm. The division is to break the prior x likelihood target into a product such that some terms are much cheaper than others. Or equivalently to represent the acceptance-rejection ratio in the Metropolis-Hastings algorithm as
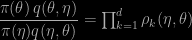
again with significant differences in the computing cost of those terms. Indeed, this division can be exploited by checking for each term sequentially, in the sense that the overall acceptance probability
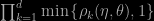
is associated with the right (posterior) target! This lemma can be directly checked via the detailed balance condition, but it is also a consequence of a 2005 paper by Andrès Christen and Colin Fox on using approximate transition densities (with the same idea of gaining time: in case of an early rejection, the exact target needs not be computed). While the purpose of the recent [commented] paper by Doucet et al. is fundamentally orthogonal to ours, a special case of this decomposition of the acceptance step in the Metropolis–Hastings algorithm can be found therein. The division of the likelihood into parts also allows for a precomputation of the target solely based on a subsample, hence gaining time and allowing for a natural prefetching version, following recent developments in this direction. (Discussed on the ‘Og.) We study the novel method within two realistic environments, the fi rst one made of logistic regression targets using benchmarks found in the earlier prefetching literature and a second one handling an original analysis of a parametric mixture model via genuine Jeffreys priors. [As I made preliminary notes along those weeks using the ‘Og as a notebook, several posts on the coming days will elaborate on the above.]

June 13, 2017 at 1:45 am
[…] cases when thinning can be hard-wired by simulating directly a k-step move, delaying rejection or acceptance, prefetching, or simulating directly the accepted values as in our vanilla Rao-Blackwellisation […]
June 12, 2014 at 7:09 pm
Dear Prof. Xi’an,
A couple years back, I had a similar idea to that in the new paper. It is based on the same decomposition. using your notation:
If you let R_k = Prod_(i=1:k) {rho_i}, then acceptance rate= min{1,R_1,R_2,…R_d}, will also satisfy detailed balance. The caveat is that at the proposal stage, for any proposed ordering of the factors (rho_1,rho_2,…rho_d), the reverse ordering (rho_d,…rho_2,rho_1) must be chosen with equal probability. Note the difference here, is that you draw *one* univariate u, and reject the first time R_k < u. (Detailed balance is not too tough to prove)
The goal for my old idea is obviously different than in you and your co-author's paper. In my idea, choosing a clever ordering for the factors is harder or less fruitful because you must use the reverse ordering just as frequently. But it should be more optimal in the sense of (acceptance probability)/(number of factors needing to be computed).
I'm not a statistician, just a lonely crank- but I'd love if you gave my idea a brief look :)
June 12, 2014 at 10:59 pm
Thank you Philp for the suggestion. I checked by simulation on my normal and binomial toy benchmarks that it worked and indeed the symmetry in the choice of the orderings seems a requirement! My crude intuition at this stage is that using a single uniform could induce a slower convergence but using the partial products and a random ordering allows for some compensation and thus potentially a larger overall probability of acceptance. For instance, here is what I get on a binomial example:
> acrat #acceptance rate with your formula:
[1] 0.47781 0.46050 0.45769 0.43785 0.43067 0.43065
> acrat #acceptance rate with our formula
[1] 0.29379 0.22479 0.19637 0.16480 0.12892 0.09349
> system.time(source(“betabin.R”)) #ours
user system elapsed
12.269 0.060 12.669
> system.time(source(“betamin.R”)) #yours
user system elapsed
12.853 0.036 13.040
I will most likely re-blog your suggestion and we will run further tests with my students. Thanks again!
June 13, 2014 at 2:00 pm
Thanks for looking- More than I could have hoped for! I think your crude intuition matches mine. To continue crudely, the mins of partial products seem to preserve more info from previously calculated factors than partial products of mins. To me it seems the major downside is the required symmetry in ordering.
Thanks again for having a look!
June 13, 2014 at 12:24 pm
Actually, I did not time things correctly, so here is the timing comparison for a Bin(100,p) example:
> system.time(source(“letamin.R”)) #yours
user system elapsed
58.131 0.052 58.848
> system.time(source(“letabin.R”)) #ours
user system elapsed
48.840 0.028 49.173
which makes a bit more sense. The overall comparison between both approaches should eventually rest on the computing cost of each individual term…
June 12, 2014 at 8:45 am
[…] P.S. More from X here. […]