Statistical Modeling with R (A dual frequentist and Bayesian approach for life scientists) is a recent book written by Pablo Inchausti, from Uruguay. In a highly personal and congenial style (witness the preface), with references to (fiction) books that enticed me to buy them. The book was sent to me by the JASA book editor for review and I went through the whole of it during my flight back from Jeddah. [Disclaimer about potential self-plagiarism: this post or a likely edited version of it will eventually appear in JASA. If not CHANCE, for once.]
The very first sentence (after the preface) quotes my late friend Steve Fienberg, which is definitely starting on the right foot. The exposition of the motivations for writing the book is quite convincing, with more emphasis than usual put on the notion and limitations of modeling. The discourse is overall inspirational and contains many relevant remarks and links that make it worth reading it as a whole. While heavily connected with a few R packages like fitdist, fitistrplus, brms (a front for Stan), glm, glmer, the book is wisely bypassing the perilous reef of recalling R bases. Similarly for the foundations of probability and statistics. While lacking in formal definitions, in my opinion, it reads well enough to somehow compensate for this very lack. I also appreciate the coherent and throughout continuation of the parallel description of Bayesian and non-Bayesian analyses, an attempt that often too often quickly disappear in other books. (As an aside, note that hardly anyone claims to be a frequentist, except maybe Deborah Mayo.) A new model is almost invariably backed by a new dataset, if a few being somewhat inappropriate as in the mammal sleep patterns of Chapter 5. Or in Fig. 6.1.
Given that the main motivation for the book (when compared with references like BDA) is heavily towards the practical implementation of statistical modelling via R packages, it is inevitable that a large fraction of Statistical Modeling with R is spent on the analysis of R outputs, even though it sometimes feels a wee bit too heavy for yours truly. The R screen-copies are however produced in moderate quantity and size, even though the variations in typography/fonts (at least on my copy?!) may prove confusing. Obviously the high (explosive?) distinction between regression models may eventually prove challenging for the novice reader. The specific issue of prior input (or “defining priors”) is briefly addressed in a non-chapter (p.323), although mentions are made throughout preceding chapters. I note the nice appearance of hierarchical models and experimental designs towards the end, but would have appreciated some discussions on missing topics such as time series, causality, connections with machine learning, non-parametrics, model misspecification. As an aside, I appreciated being reminded about the apocryphal nature of Ockham’s much cited quote “Pluralitas non est ponenda sine necessitate“.
Typo Jeffries found in Fig. 2.1, along with a rather sketchy representation of the history of both frequentist and Bayesian statistics. And Jon Wakefield’s book (with related purpose of presenting both versions of parametric inference) was mistakenly entered as Wakenfield’s in the bibliography file. Some repetitions occur. I do not like the use of the equivalence symbol ≈ for proportionality. And I found two occurrences of the unavoidable “the the” typo (p.174 and p.422). I also had trouble with some sentences like “long-run, hypothetical distribution of parameter estimates known as the sampling distribution” (p.27), “maximum likelihood estimates [being] sufficient” (p.28), “Jeffreys’ (1939) conjugate priors” [which were introduced by Raiffa and Schlaifer] (p.35), “A posteriori tests in frequentist models” (p.130), “exponential families [having] limited practical implications for non-statisticians” (p.190), “choice of priors being correct” (p.339), or calling MCMC sample terms “estimates” (p.42), and issues with some repetitions, missing indices for acronyms, packages, datasets, but did not bemoan the lack homework sections (beyond suggesting new datasets for analysis).
A problematic MCMC entry is found when calibrating the choice of the Metropolis-Hastings proposal towards avoiding negative values “that will generate an error when calculating the log-likelihood” (p.43) since it suggests proposed values should not exceed the support of the posterior (and indicates a poor coding of the log-likelihood!). I also find the motivation for the full conditional decomposition behind the Gibbs sampler (p.47) unnecessarily confusing. (And automatically having a Metropolis-Hastings step within Gibbs as on Fig. 3.9 brings another magnitude of confusion.) The Bayes factor section is very terse. The derivation of the Kullback-Leibler representation (7.3) as an expected log likelihood ratio seems to be missing a reference measure. Of course, seeing a detailed coverage of DIC (Section 7.4) did not suit me either, even though the issue with mixtures was alluded to (with no detail whatsoever). The Nelder presentation of the generalised linear models felt somewhat antiquated, since the addition of the scale factor a(φ) sounds over-parameterized.
But those are minor quibble in relation to a book that should attract curious minds of various background knowledge and expertise in statistics, as well as work nicely to support an enthusiastic teacher of statistical modelling. I thus recommend this book most enthusiastically.




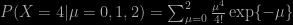 ,
,
