Split Sampling: expectations, normalisation and rare events
Just before Christmas (a year ago), John Birge, Changgee Chang, and Nick Polson arXived a paper with the above title. Split sampling is presented a a tool conceived to handle rare event probabilities, written in this paper as
![Z(m)=\mathbb{E}_\pi[\mathbb{I}\{L(X)>m\}]](https://s0.wp.com/latex.php?latex=Z%28m%29%3D%5Cmathbb%7BE%7D_%5Cpi%5B%5Cmathbb%7BI%7D%5C%7BL%28X%29%3Em%5C%7D%5D&bg=000000&fg=B0B0B0&s=0&c=20201002)
where π is the prior and L the likelihood, m being a large enough bound to make the probability small. However, given John Skilling’s representation of the marginal likelihood as the integral of the Z(m)’s, this simulation technique also applies to the approximation of the evidence. The paper refers from the start to nested sampling as a motivation for this method, presumably not as a way to run nested sampling, which was created as a tool for evidence evaluation, but as a competitor. Nested sampling may indeed face difficulties in handling the coverage of the higher likelihood regions under the prior and it is an approximative method, as we detailed in our earlier paper with Nicolas Chopin. The difference between nested and split sampling is that split sampling adds a distribution ω(m) on the likelihood levels m. If pairs (x,m) can be efficiently generated by MCMC for the target
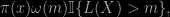
the marginal density of m can then be approximated by Rao-Blackwellisation. From which the authors derive an estimate of Z(m), since the marginal is actually proportional to ω(m)Z(m). (Because of the Rao-Blackwell argument, I wonder how much this differs from Chib’s 1995 method, i.e. if the split sampling estimator could be expressed as a special case of Chib’s estimator.) The resulting estimator of the marginal also requires a choice of ω(m) such that the associated cdf can be computed analytically. More generally, the choice of ω(m) impacts the quality of the approximation since it determines how often and easily high likelihood regions will be hit. Note also that the conditional π(x|m) is the same as in nested sampling, hence may run into difficulties for complex likelihoods or large datasets.
When reading the beginning of the paper, the remark that “the chain will visit each level roughly uniformly” (p.13) made me wonder at a possible correspondence with the Wang-Landau estimator. Until I read the reference to Jacob and Ryder (2012) on page 16. Once again, I wonder at a stronger link between both papers since the Wang-Landau approach aims at optimising the exploration of the simulation space towards a flat histogram. See for instance Figure 2.
The following part of the paper draws a comparison with both nested sampling and the product estimator of Fishman (1994). I do not fully understand the consequences of the equivalence between those estimators and the split sampling estimator for specific choices of the weight function ω(m). Indeed, it seemed to me that the main point was to draw from a joint density on (x,m) to avoid the difficulties of exploring separately each level set. And also avoiding the approximation issues of nested sampling. As a side remark, the fact that the harmonic mean estimator occurs at several points of the paper makes me worried. The qualification of “poor Monte Carlo error variances properties” is an understatement for the harmonic mean estimator, as it generally has infinite variance and it hence should not be used at all, even as a starting point. The paper does not elaborate much about the cross-entropy method, despite using an example from Rubinstein and Kroese (2004).
In conclusion, an interesting paper that made me think anew about the nested sampling approach, which keeps its fascination over the years! I will most likely use it to build an MSc thesis project this summer in Warwick.

Leave a comment