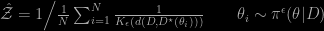A recent paper on evidence by Anindya Bhadra, Ksheera Sagar, Sayantan Banerjee (whom I met during Rito’s seminar, since he was also visiting Ismael in Paris, and who mentioned this work), and Jyotishka Datta, on computing the evidence for graphical models. Obtaining an approximation of the evidence attached with a model and a prior on the covariance matrix Ω is a challenge they manage to address in a particularly clever manner.
A recent paper on evidence by Anindya Bhadra, Ksheera Sagar, Sayantan Banerjee (whom I met during Rito’s seminar, since he was also visiting Ismael in Paris, and who mentioned this work), and Jyotishka Datta, on computing the evidence for graphical models. Obtaining an approximation of the evidence attached with a model and a prior on the covariance matrix Ω is a challenge they manage to address in a particularly clever manner.
“the conditional posterior density [of the last column of the covariance matrix] can be evaluated as a product of normal and gamma densities under suitable priors (…) We resolve this [difficulty with the integrated likelihood] by evaluating the required densities in one row or column at a time, and proceeding backwards starting from the p-th row, with appropriate adjustments to Ωp×p at each step via Schur complement. “
Using a telescoping trick, the authors exploit the fact that the decomposition

involves a problematic second term that can be ignored by successive cancellations, as shown by Figure 1. The other terms are manageable for some classes of priors on Ω. Like a Wishart. This allows them to call for Chib’s (two-black) method, which requires two independent MCMC runs. Actually, an unfortunate aspect of the approach is that its computational complexity is of order O(M p⁵), where M is the number of MCMC samples, due to the telescopic trick involving calling Chib’s approach for each of the p columns of Ω. While the numerical outcomes compare with nested sampling, annealed importance sampling, and even harmonic mean estimates (!), the computing time usually exceeds those for these other methods, esp. harmonic mean estimates For the specific G-Wishart case, the solution proposed by Atay-Kayis and Massam (2005) proves far superior. Since the main purpose of using evidence is in deriving Bayes factors, I wonder at possible gains in recycling simulations between models, even though this would seem to call for bridge sampling, no considered in the paper.
 In a recent
In a recent 

 Following a
Following a