the demise of the Bayes factor

With Kaniav Kamary, Kerrie Mengersen, and Judith Rousseau, we have just arXived (and submitted) a paper entitled “Testing hypotheses via a mixture model”. (We actually presented some earlier version of this work in Cancũn, Vienna, and Gainesville, so you may have heard of it already.) The notion we advocate in this paper is to replace the posterior probability of a model or an hypothesis with the posterior distribution of the weights of a mixture of the models under comparison. That is, given two models under comparison,
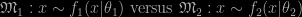
we propose to estimate the (artificial) mixture model

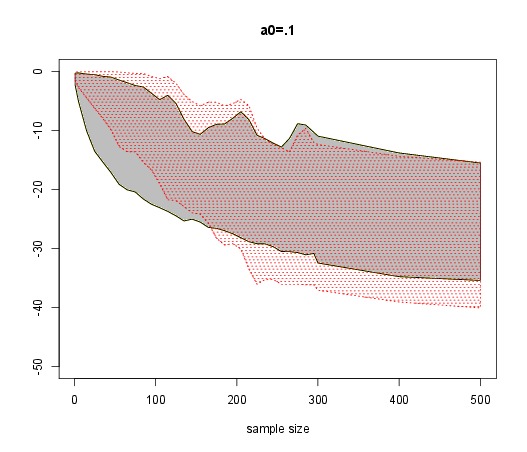
and in particular derive the posterior distribution of α. One may object that the mixture model is neither of the two models under comparison but this is the case at the boundary, i.e., when α=0,1. Thus, if we use prior distributions on α that favour the neighbourhoods of 0 and 1, we should be able to see the posterior concentrate near 0 or 1, depending on which model is true. And indeed this is the case: for any given Beta prior on α, we observe a higher and higher concentration at the right boundary as the sample size increases. And establish a convergence result to this effect. Furthermore, the mixture approach offers numerous advantages, among which [verbatim from the paper]:
- relying on a Bayesian estimator of the weight α rather than on the posterior probability of the corresponding model does remove the need of overwhelmingly artificial prior probabilities on model indices;
- the interpretation of this estimator is at least as natural as handling the posterior probability, while avoiding the caricaturesque zero-one loss setting. The quantity α and its posterior distribution provide a measure of proximity to both models for the data at hand, while being also interpretable as a propensity of the data to stand with (or to stem from) one of the two models. This representation further allows for alternative perspectives on testing and model choices, through the notions of predictive tools cross-validation, and information indices like WAIC;
- the highly problematic computation of the marginal likelihoods is bypassed, standard algorithms being available for Bayesian mixture estimation;
- the extension to a finite collection of models to be compared is straightforward, as this simply involves a larger number of components. This approach further allows to consider all models at once rather than engaging in pairwise costly comparisons and thus to eliminate the least likely models by simulation, those being not explored by the corresponding algorithm;
- the (simultaneously conceptual and computational) difficulty of “label switching” that plagues both Bayesian estimation and Bayesian computation for most mixture models completely vanishes in this particular context, since components are no longer exchangeable. In particular, we compute neither a Bayes factor nor a posterior probability related with the substitute mixture model and we hence avoid the difficulty of recovering the modes of the posterior distribution. Our perspective is solely centred on estimating the parameters of a mixture model where both components are always identifiable;
- the posterior distribution of α evaluates more thoroughly the strength of the support for a given model than the single figure outcome of a Bayes factor or of a posterior probability. The variability of the posterior distribution on α allows for a more thorough assessment of the strength of the support of one model against the other;
- an additional feature missing from traditional Bayesian answers is that a mixture model also acknowledges the possibility that, for a finite dataset, both models or none could be acceptable.
- while standard (proper and informative) prior modelling can be painlessly reproduced in this novel setting, non-informative (improper) priors now are manageable therein, provided both models under comparison are first reparametrised towards common-meaning and shared parameters, as for instance with location and scale parameters. In the special case when all parameters can be made common to both models [While this may sound like an extremely restrictive requirement in a traditional mixture model, let us stress here that the presence of common parameters becomes quite natural within a testing setting. To wit, when comparing two different models for the same data, moments are defined in terms of the observed data and hence should be the same for both models. Reparametrising the models in terms of those common meaning moments does lead to a mixture model with some and maybe all common parameters. We thus advise the use of a common parametrisation, whenever possible.] the mixture model reads as
For instance, if θ is a location parameter, a flat prior can be used with no foundational difficulty, in opposition to the testing case;
- continuing from the previous argument, using the same parameters or some identical parameters on both components is an essential feature of this reformulation of Bayesian testing, as it highlights the fact that the opposition between the two components of the mixture is not an issue of enjoying different parameters, but quite the opposite. As further stressed below, this or even those common parameter(s) is (are) nuisance parameters that need be integrated out (as they also are in the traditional Bayesian approach through the computation of the marginal likelihoods);
- the choice of the prior model probabilities is rarely discussed in a classical Bayesian approach, even though those probabilities linearly impact the posterior probabilities and can be argued to promote the alternative of using the Bayes factor instead. In the mixture estimation setting, prior modelling only involves selecting a prior on α, for instance a Beta B(a,a) distribution, with a wide range of acceptable values for the hyperparameter a. While the value of a impacts the posterior distribution of α, it can be argued that (a) it nonetheless leads to an accumulation of the mass near 1 or 0, i.e., to favour the most favourable or the true model over the other one, and (b) a sensitivity analysis on the impact of a is straightforward to carry on;
- in most settings, this approach can furthermore be easily calibrated by a parametric bootstrap experiment providing a posterior distribution of α under each of the models under comparison. The prior predictive error can therefore be directly estimated and can drive the choice of the hyperparameter a, if need be.

March 10, 2017 at 6:13 pm
[…] peers of Science with capital letter. The second part of the comments is highly supportive of our mixture approach and I obviously appreciate very much this support! Especially if we ever manage to turn the paper […]
December 10, 2014 at 5:03 pm
“The quantity α and its posterior distribution provide a measure of proximity to both models for the data at hand, while being also interpretable as a propensity of the data to stand with (or to stem from) one of the two models.”
To built on the remark by Dan Simpson: if we do a standard model selection via BF or alike, we only compare the ability of two (or more) model structures to conform with the data. If we formulate the model selection via a mixture model, we are essentially offering a number of additional intermediate models, which could have very different properties in terms of distribution etc.
So, if I get an alpha = 0.5, I wonder how we can distinguish whether both models are equally likely given the data, or whether the mixture is a lot more likely that either of the two.
Side remark, but this is just semantics: I wondered why you used “testing hypotheses” and not “model selection” in the title.
December 10, 2014 at 8:38 pm
Thanks, Florian. I completely agree that, if α has a posterior around 0.5, the main conclusion is that a mixture is the closest to the “true” model in the KL sense. I should rephrase this sentence…
And about the title: Testing sounded more generic and encompassing that Model choice or Model selection, I presume, so since we wanted to address the general problem it seemed more appropriate to use Testing… Of course, this is mostly a posteriori rationalisation.
December 10, 2014 at 3:41 pm
I suppose this approach might have a particular advantage for controlling the false discovery rate if you have multiple related hypothesis tests to conduct: in which case one would use a shared hyper prior on alpha perhaps? I have an astronomical example where there are many physically-separate clusters (of stars, & hence data), each of which we would like to examine preference for either a one component Normal or a two component Normal mixture. I’d like to learn alpha (your mixture of hypotheses alpha, as opposed the the mixture weights of the two Normal model) for each, sharing hyper parameters (e.g. on the underlying mean or variance) between matched models (i.e. between the one-components and two-components).
December 10, 2014 at 8:39 pm
Sounds most interesting! If you have time to discuss it with me when I am in Oxford, second half of January…?! I’d love to.
December 10, 2014 at 9:32 pm
Great, I should be there for most of that time; except when I’m at the BASP conference ( http://www.baspfrontiers.org ) at the very end of the month!
December 11, 2014 at 11:26 am
I think on of Dunson’s paper has asymptotics for a similar problem. It’s not quite the same (the thetas aren’t inferred), but by putting an appropriate dirichlet prior on the weights, they got optimal behaviour. I imagine that would work here too.
December 12, 2014 at 7:48 am
Dan, do you have a more precise reference for David Dunson’s paper? and a link?
December 12, 2014 at 10:38 pm
I was thinking of this: http://arxiv.org/pdf/1403.1345.pdf
But as I said, it’s a differnt problem to the one you’re considering.
December 8, 2014 at 2:13 pm
Thank you, Professor Robert. I’ll read the paper this afternoon. One part of the post that puzzles me is when you say “if θ is a location parameter, a flat prior can be used with no foundational difficulty, in opposition to the testing case”. For example, if the competing models are N(0,1) and N(θ,1), with n observations, the likelihood of the mixture satisfies log{L(α,θ)} > n log{α)+log{φ(x1)}+…+log{φ(xn)}. But then, using any beta prior for α and an independent flat prior for θ the posterior π(α,θ|x) would be improper. I’ll comment again after carefully reading the paper. Thanks.
December 8, 2014 at 2:18 pm
Thanks Paulo: let me explain better this point since it is crucial in our arguments: your example is such that θ is not a location parameter, i.e. the mixture density there is not of the form f(x-θ) because θ only appears in the second component. To validate the use of an improper prior on θ requires that θ appears in every and each component of the mixture. (I edited your comment to get rid of the LaTeX formulas that do not look that great with the blog output!)
December 8, 2014 at 12:56 pm
When neither model fit, this will converge to the mixture that minimizes the KL divergence between the “data generating mechanism” and the mixture. I can’t see how you distinguish this from both models fitting (point 7 in the list above).
I also wonder how, in finite samples, the prior on alpha affects this. Given that suggestions for alpha put almost all of the mass at the edges, it seems that this will be important. Perhaps putting a prior directly on the log proportion suggested by coreyyanofsky would be a safer move?
December 8, 2014 at 4:13 pm
You can easily view the Beta prior as being directly on log-proportion-ratio: for α_0 = 1 it’s almost a “standard” logistic distribution; other values of α_0 are equivalent to taking the logistic density to that power.
December 8, 2014 at 6:43 pm
Dan: This was not a very deep remark of mine’s, I am afraid. You are right that on principle and asymptotically the KL-optimal mixture should emerge from the mixture estimation, so obtaining a posterior on α that shies away from the boundaries is a sign of poor fit indeed! We will look at this misspecified case in a near future. The second part of the remark is also of interest. I think that we somewhat proved that even with Be(a,a) and a>1 we get a concentration at one boundary. I am however looking forward analysing the prior suggested by Corey!
December 8, 2014 at 9:11 pm
I’d actually suggest looking at the log of the marginal likelihood of ω = log(α/(1 – α)) (marginalized to be free of model-specific or moment-encoding parameters). You’ll need a prior on ω for the MCMC computation, but if you turn the resulting samples into a log-posterior-density estimate, you can just subtract off the log-prior (and, if you want, add back any other log-prior to get the correct log-posterior). The caveat is that ω and the model-specific parameters must be independent in the joint prior, but I believe that makes sense in this context…
This is analogous to how a Bayes factor can be computed by MCMC (with, say, the Carlin&Chib pseudo-prior approach, or RJMCMC) by picking a working prior over model probabilities and then taking the ratio of the posterior model probability to the prior model probability. And just as *that* working prior ought to be chosen for its computational properties, I would argue that MCMC in the estimation-as-model-testing setting should use a working prior chosen (or tuned on-line!) to provide good MCMC performance.
December 8, 2014 at 6:13 am
“In the [N (µ, 1)] case, obtaining values of α close to one requires larger sample sizes than in the [N (0, 1)] case.”
If I recall correctly, the Bayes factor has similar behavior, and Val Johnson’s non-local prior densities can yield Bayes factors that have the same rate of convergence under either model. I wonder if the non-local prior approach can be adapted to do that in the present mixture model context…
December 8, 2014 at 7:24 am
I am somewhat reluctant to consider non-local priors as they sound a-Bayesian to me…
December 8, 2014 at 1:02 pm
If I read the asymptotics right (and I may not have – it was a fast read), the posterior on alpha has almost root-n contraction, and the penalty for nested models is only a higher power in the log term. This is a far smaller asymmetry than Bayes factors (and even than the non-local fix), so it may be less relevant in practice.
It also makes sense to me that, for a predictive criterion like this, you would need more data to distinguish a single model from the “convex combination”.
December 8, 2014 at 4:18 pm
Hence my use of the word “adapted” (instead of, say, “adopted”).
;-)
December 8, 2014 at 5:59 am
“We also point out that, due to the specific pattern of the posterior distribution on α accumulating most of its weight on the endpoints of (0, 1), the use of the posterior mean is highly inefficient and thus we advocate that the posterior median be instead used as the relevant estimator of α.”
Instead of either of those alternatives, I think it’s more sensible to look at the posterior distribution of ω = log(α/(1 – α)). That transformation has a nice interpretation as the log-ratio of the proportions of data under each model, and the mean should work fine.
December 8, 2014 at 7:23 am
Thanks, Corey, this is indeed a version to include in the revised version!
December 8, 2014 at 5:42 am
Just before Section 2 there’s a typo: “hyperameters”.
December 8, 2014 at 7:08 am
Thanks! (Even though I do like this hype parameter…)