estimating a constant
Paulo (a.k.a., Zen) posted a comment in StackExchange on Larry Wasserman‘s paradox about Bayesians and likelihoodists (or likelihood-wallahs, to quote Basu!) being unable to solve the problem of estimating the normalising constant c of the sample density, f, known up to a constant

(Example 11.10, page 188, of All of Statistics)
My own comment is that, with all due respect to Larry!, I do not see much appeal in this example, esp. as a potential criticism of Bayesians and likelihood-wallahs…. The constant c is known, being equal to

If c is the only “unknown” in the picture, given a sample x1,…,xn, then there is no statistical issue whatsoever about the “problem” and I do not agree with the postulate that there exist estimators of c. Nor priors on c (other than the Dirac mass on the above value). This is not in the least a statistical problem but rather a numerical issue.That the sample x1,…,xn can be (re)used through a (frequentist) density estimate to provide a numerical approximation of c

is a mere curiosity. Not a criticism of alternative statistical approaches: e.g., I could also use a Bayesian density estimate…
Furthermore, the estimate provided by the sample x1,…,xn is not of particular interest since its precision is imposed by the sample size n (and converging at non-parametric rates, which is not a particularly relevant issue!), while I could use importance sampling (or even numerical integration) if I was truly interested in c. I however find the discussion interesting for many reasons
- it somehow relates to the infamous harmonic mean estimator issue, often discussed on the’Og!;
- it brings more light on the paradoxical differences between statistics and Monte Carlo methods, in that statistics is usually constrained by the sample while Monte Carlo methods have more freedom in generating samples (up to some budget limits). It does not make sense to speak of estimators in Monte Carlo methods because there is no parameter in the picture, only “unknown” constants. Both fields rely on samples and probability theory, and share many features, but there is nothing like a “best unbiased estimator” in Monte Carlo integration, see the case of the “optimal importance function” leading to a zero variance;
- in connection with the previous point, the fascinating Bernoulli factory problem is not a statistical problem because it requires an infinite sequence of Bernoullis to operate;
- the discussion induced Chris Sims to contribute to StackExchange!

October 6, 2012 at 3:02 am
[…] Robert discussed the problem on his blog. If I understand what Christian has written, he claims that this cannot be considered a statistical […]
October 3, 2012 at 3:13 pm
Christian
I don’t know why you keep calling it “known.”
Known means: you know it. But you don’t know it!
To estimate the normalizing constant of a posterior from
simulated values, what method do you use?
Frequentist or Bayes? If bayes, how do you do it?
By the way, credit where credit is due: the example is
due to Ed!
Best wishes
Larry
October 3, 2012 at 6:34 pm
When I am using simulation, or Monte Carlo methods, I rely on the law of large numbers and the stabilisation of frequencies. So Monte Carlo is a ‘frequentist” method, granted, but it is not connected with a statistical issue, which is why I find the debate “frequentist vs. Bayesian” rather vacuous here…
October 3, 2012 at 4:23 am
Agree it’s a terrible example. Larry W’s claim there is no Bayesian estimate of the normalizing constant seems equivalent to claiming there is no Bayesian estimate of the 5th decimal place of pi.
October 3, 2012 at 6:50 am
Indeed, I think that, in both cases, we should not use the wording estimate, but instead the wording approximation.
October 3, 2012 at 2:13 am
Christian:
A parameter theta is a fixed constat.
But until you know it, as a Bayesian, you treat it as a random
variable.
Why not the same for c?
–Larry
October 3, 2012 at 6:49 am
Hi, Larry! The constant c is known in this case, which makes all the difference with an unknown parameter driving the distribution of an observed sample. For instance, I cannot make observations about c, I cannot build a likelihood on c, &tc… At a more subtle level, we should get back to what Persi suggested as Bayesian numerical analysis (in the 1992 Purdue Symposium?).
October 3, 2012 at 1:01 am
“But if we still try to play this artificial game introducing a random normalization constant C,” may actually be the strangest thing I’ve ever seen on the internet.
How is this even possibly nearly an argument? It blows my mind.
I know that we often say that in Bayesian statistics “everything is random”, but we don’t actually mean it!
Further down the thread “Suppose you can’t do the numerical integral”………. Is Wasserman actually saying “suppose f is not in L2”?
October 3, 2012 at 1:08 am
Actually on further thought, this is only completely trivial if the density is absolutely continuous. If it isn’t then the summation in the normalising constant can be tricky.
That being said, there are at least 3 methods that I can think of (as a non-expert) for doing non-paradoxical inference with uncomputable normalising constants. And those constants still aren’t random!
October 3, 2012 at 6:41 am
You never know what the next strangest thing on the internet can be..! As a Bayesian I do not say that everything is random, rather that using a probability distribution (or a measure) is the optimal way to represent my uncertainty about things, like non-random parameters driving a random phenomena. In the current case, my prior distribution is a Dirac mass.
October 10, 2012 at 4:42 pm
Might help to distinguish (uncertainty of) actualities from potentialities (CS Peirce vocabulary) as for instance actualities are (must be) discrete and finite (e.g. non-random parameters driving a random phenomena in _this_ universe) while potentialities must be any logically allowed possibly continuous quantity (exactly).
I would agree that statistical problems and estimates should be about (uncertainty of) actualities, but the real importance of vocabulary is that the community can agree on it. Hopefully people might agree that there should be such a distinction (actualities from potentialities) if only to avoid a lot of confusion.
October 3, 2012 at 12:30 am
As a subjective Bayesian, can you elicit the prior that the 100-th digit of pi is 7? For me this is the same problem, but I’ve heard some Bayesians saying it is fine to do it.
October 3, 2012 at 6:37 am
If you only consider the 100th digit of π, I would indeed say it is a similar issue: using a series representation of π eventually leads to this 100th digit. And there is no clear “observation” I can gather about this 100th digit… If now you are interested in the distribution of the digits of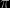 , this is another issue: I have observations and I can put a prior of the distribution. (Not that it will answer the on-going mathematical question about the randomness of the digits of π, obviously!)
, this is another issue: I have observations and I can put a prior of the distribution. (Not that it will answer the on-going mathematical question about the randomness of the digits of π, obviously!)
October 3, 2012 at 3:34 pm
Well, we can “estimate” pi by generating data in a square and counting the proportion of points that fall inside the circle inside the square http://yichuanshen.de/blog/2012/01/06/monte-carlo-pi/ We could do this in a Bayesian way as well by putting a prior on pi. The Binomial likelihood here is defined for every value of pi (which is not true in Larry’s example), even though there is only one true value.
October 3, 2012 at 8:39 pm
Yes, this is an example I used in my public lecture in Australia (and that my daughter also learned in secondary school). However, this is not a statistical problem, in my opinion, rather a stochastic approximation to this unique and known number.