In a complete coincidence with my visit to Warwick this week, I became aware of the paper “Inference in two-piece location-scale models with Jeffreys priors” recently published in Bayesian Analysis by Francisco Rubio and Mark Steel, both from Warwick. Paper where they exhibit a closed-form Jeffreys prior for the skewed distribution
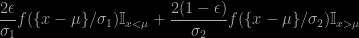
where f is a symmetric density, namely
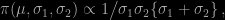
where

only to show immediately after that this prior does not allow for a proper posterior, no matter what the sample size is. While the above skewed distribution can always be interpreted as a mixture, being a weighted sum of two terms, it is not strictly speaking a mixture, if only because the “component” can be identified from the observation (depending on which side of μ is stands). The likelihood is therefore a product of simple terms rather than a product of a sum of two terms.
As a solution to this conundrum, the authors consider the alternative of the “independent Jeffreys priors”, which are made of a product of conditional Jeffreys priors, i.e., by computing the Jeffreys prior one parameter at a time with all other parameters considered to be fixed. Which differs from the reference prior, of course, but would have been my second choice as well. Despite criticisms expressed by José Bernardo in the discussion of the paper… The difficulty (in my opinion) resides in the choice (and difficulty) of the parameterisation of the model, since those priors are not parameterisation-invariant. (Xinyi Xu makes the important comment that even those priors incorporate strong if hidden information. Which relates to our earlier discussion with Kaniav Kamari on the “dangers” of prior modelling.)
Although the outcome is puzzling, I remain just slightly sceptical of the income, namely Jeffreys prior and the corresponding Fisher information: the fact that the density involves an indicator function and is thus discontinuous in the location μ at the observation x makes the likelihood function not differentiable and hence the derivation of the Fisher information not strictly valid. Since the indicator part cannot be differentiated. Not that I am seeing the Jeffreys prior as the ultimate grail for non-informative priors, far from it, but there is definitely something specific in the discontinuity in the density. (In connection with the later point, Weiss and Suchard deliver a highly critical commentary on the non-need for reference priors and the preference given to a non-parametric Bayes primary analysis. Maybe making the point towards a greater convergence of the two perspectives, objective Bayes and non-parametric Bayes.)
This paper and the ensuing discussion about the properness of the Jeffreys posterior reminded me of our earliest paper on the topic with Jean Diebolt. Where we used improper priors on location and scale parameters but prohibited allocations (in the Gibbs sampler) that would lead to less than two observations per components, thereby ensuring that the (truncated) posterior was well-defined. (This feature also remained in the Series B paper, submitted at the same time, namely mid-1990, but only published in 1994!) Larry Wasserman proved ten years later that this truncation led to consistent estimators, but I had not thought about it in very long while. I still like this notion of forcing some (enough) datapoints into each component for an allocation (of the latent indicator variables) to be an acceptable Gibbs move. This is obviously not compatible with the iid representation of a mixture model, but it expresses the requirement that components all have a meaning in terms of the data, namely that all components contributed to generating a part of the data. This translates as a form of weak prior information on how much we trust the model and how meaningful each component is (in opposition to adding meaningless extra-components with almost zero weights or almost identical parameters).
As a marginalia, the insistence in Rubio and Steel’s paper that all observations in the sample be different also reminded me of a discussion I wrote for one of the Valencia proceedings (Valencia 6 in 1998) where Mark presented a paper with Carmen Fernández on this issue of handling duplicated observations modelled by absolutely continuous distributions. (I am afraid my discussion is not worth the $250 price tag given by amazon!)
 Fangzheng Xie and Yanxun Xu arXived today a paper on Bayesian repulsive modelling for mixtures. Not that Bayesian modelling is repulsive in any psychological sense, but rather that the components of the mixture are repulsive one against another. The device towards this repulsiveness is to add a penalty term to the original prior such that close means are penalised. (In the spirit of the sugar loaf with water drops represented on the cover of Bayesian Choice that we used in our pinball sampler, repulsiveness being there on the particles of a simulated sample and not on components.) Which means a prior assumption that close covariance matrices are of lesser importance. An interrogation I
Fangzheng Xie and Yanxun Xu arXived today a paper on Bayesian repulsive modelling for mixtures. Not that Bayesian modelling is repulsive in any psychological sense, but rather that the components of the mixture are repulsive one against another. The device towards this repulsiveness is to add a penalty term to the original prior such that close means are penalised. (In the spirit of the sugar loaf with water drops represented on the cover of Bayesian Choice that we used in our pinball sampler, repulsiveness being there on the particles of a simulated sample and not on components.) Which means a prior assumption that close covariance matrices are of lesser importance. An interrogation I 




 Deborah Mayo wrote a
Deborah Mayo wrote a 