cut, baby, cut!
 At MCMSki IV, I attended (and chaired) a session where Martyn Plummer presented some developments on cut models. As I was not sure I had gotten the idea [although this happened to be one of those few sessions where the flu had not yet completely taken over!] and as I wanted to check about a potential explanation for the lack of convergence discussed by Martyn during his talk, I decided to (re)present the talk at our “MCMSki decompression” seminar at CREST. Martyn sent me his slides and also kindly pointed out to the relevant section of the BUGS book, reproduced above. (Disclaimer: do not get me wrong here, the title is a pun on the infamous “drill, baby, drill!” and not connected in any way to Martyn’s talk or work!)
At MCMSki IV, I attended (and chaired) a session where Martyn Plummer presented some developments on cut models. As I was not sure I had gotten the idea [although this happened to be one of those few sessions where the flu had not yet completely taken over!] and as I wanted to check about a potential explanation for the lack of convergence discussed by Martyn during his talk, I decided to (re)present the talk at our “MCMSki decompression” seminar at CREST. Martyn sent me his slides and also kindly pointed out to the relevant section of the BUGS book, reproduced above. (Disclaimer: do not get me wrong here, the title is a pun on the infamous “drill, baby, drill!” and not connected in any way to Martyn’s talk or work!)
I cannot say I get the idea any clearer from this short explanation in the BUGS book, although it gives a literal meaning to the word “cut”. From this description I only understand that a cut is the removal of an edge in a probabilistic graph, however there must/may be some arbitrariness in building the wrong conditional distribution. In the Poisson-binomial case treated in Martyn’s case, I interpret the cut as simulating from

instead of
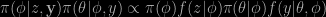
hence loosing some of the information about φ… Now, this cut version is a function of φ and θ that can be fed to a Metropolis-Hastings algorithm. Assuming we can handle the posterior on φ and the conditional on θ given φ. If we build a Gibbs sampler instead, we face a difficulty with the normalising constant m(y|φ). Said Gibbs sampler thus does not work in generating from the “cut” target. Maybe an alternative borrowing from the rather large if disparate missing constant toolbox. (In any case, we do not simulate from the original joint distribution.) The natural solution would then be to make a independent proposal on φ with target the posterior given z and then any scheme that preserves the conditional of θ given φ and y; “any” is rather wistful thinking at this stage since the only practical solution that I see is to run a Metropolis-Hasting sampler long enough to “reach” stationarity… I also remain with a lingering although not life-threatening question of whether or not the BUGS code using cut distributions provide the “right” answer or not. Here are my five slides used during the seminar (with a random walk implementation that did not diverge from the true target…):

{kind=link}
January 29, 2014 at 3:56 pm
There is a connection with partially collapsed MH, see http://arxiv.org/pdf/1309.3217v1.pdf (particularly section 2.3). They suggest that WinBUGS is/might be doing the wrong thing at the end of that section, which also uses a bivariate normal target to illustrate. But I think they were primarily concerned about (effectively) using a sampler derived from the “cut” model to get samples from the “uncut” posterior, which is obviously more problematic than simply trying to get samples from the “cut” posterior itself.
January 29, 2014 at 8:47 am
[…] article was first published on Xi'an's Og » R, and kindly contributed to […]