Bangalore workshop [ಬೆಂಗಳೂರು ಕಾರ್ಯಾಗಾರ]
 Second day at the Indo-French Centre for Applied Mathematics and the workshop. Maybe not the most exciting day in terms of talks (as I missed the first two plenary sessions by (a) oversleeping and (b) running across the campus!). However I had a neat talk with another conference participant that led to [what I think are] interesting questions… (And a very good meal in a local restaurant as the guest house had not booked me for dinner!)
Second day at the Indo-French Centre for Applied Mathematics and the workshop. Maybe not the most exciting day in terms of talks (as I missed the first two plenary sessions by (a) oversleeping and (b) running across the campus!). However I had a neat talk with another conference participant that led to [what I think are] interesting questions… (And a very good meal in a local restaurant as the guest house had not booked me for dinner!)
To wit: given a target like
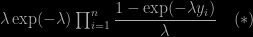
the simulation of λ can be demarginalised into the simulation of
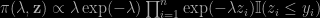
where z is a latent (and artificial) variable. This means a Gibbs sampler simulating λ given z and z given λ can produce an outcome from the target (*). Interestingly, another completion is to consider that the zi‘s are U(0,yi) and to see the quantity
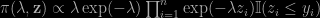
as an unbiased estimator of the target. What’s quite intriguing is that the quantity remains the same but with different motivations: (a) demarginalisation versus unbiasedness and (b) zi ∼ Exp(λ) versus zi ∼ U(0,yi). The stationary is the same, as shown by the graph below, the core distributions are [formally] the same, … but the reasoning deeply differs.

Obviously, since unbiased estimators of the likelihood can be justified by auxiliary variable arguments, this is not in fine a big surprise. Still, I had not thought of the analogy between demarginalisation and unbiased likelihood estimation previously.Here are the R procedures if you are interested:
n=29
y=rexp(n)
T=10^5
#MCMC.1
lam=rep(1,T)
z=runif(n)*y
for (t in 1:T){
lam[t]=rgamma(1,shap=2,rate=1+sum(z))
z=-log(1-runif(n)*(1-exp(-lam[t]*y)))/lam[t]
}
#MCMC.2
fam=rep(1,T)
z=runif(n)*y
for (t in 1:T){
fam[t]=rgamma(1,shap=2,rate=1+sum(z))
z=runif(n)*y
}

July 31, 2014 at 8:58 am
I thought this was Nicolas Chopin’s main thrust when talking about these pseudo-marginal algorithms: unbiasedness is a consequence, but not the important thing. The expansion/re-marginalisation is the easiest way to work with these things (because just having unbiasedness isn’t enough – you’ve got to propagate the estimates forward correctly in the accept/reject step)