, it is hard to fathom how this could help. Were the additional data be generated conditional on the current value of the model parameter, Gibbs-like, this would be correct but still counterproductive, since it would only slow down convergence to the original posterior.")
Archive for Gibbs sampler
biXarre, biXarre
Posted in Books, Statistics with tags completion, cross validated, GARCH model, Gibbs sampler, latent data, Metropolis-Hastings algorithm on May 2, 2024 by xi'an
inference with insufficient statistics #2
Posted in Books, Kids, Statistics with tags conditional sufficiency, cross validated, EM algorithm, Gibbs sampler, implementation, incomplete data, order statistics, truncated normal on December 28, 2023 by xi'an
Another X validated question of some interest: how to infer about the parameters of a model when only given a fraction 1-α of the order statistics. For instance, the (1-α)n largest observations. On a primary level, the answer is somewhat obvious since the joint density of these observations is available in closed form. At another level, it brings out the fact that the distribution of the unobserved part of the sample given the observed one only depends on the smallest observed order statistic ς (which is thus sufficient in that sense) and ends up being the original distribution truncated at ς, which allows for a closed form EM implementation. Which is also interesting given that the moments of a Normal order statistic are not available in closed form. This reminded me of the insufficient Gibbs paper we wrote with Antoine and Robin a few months ago, except for the available likelihood. And provided fodder for the final exam of my introductory mathematical statistics course at Paris Dauphine.
truncated mixtures
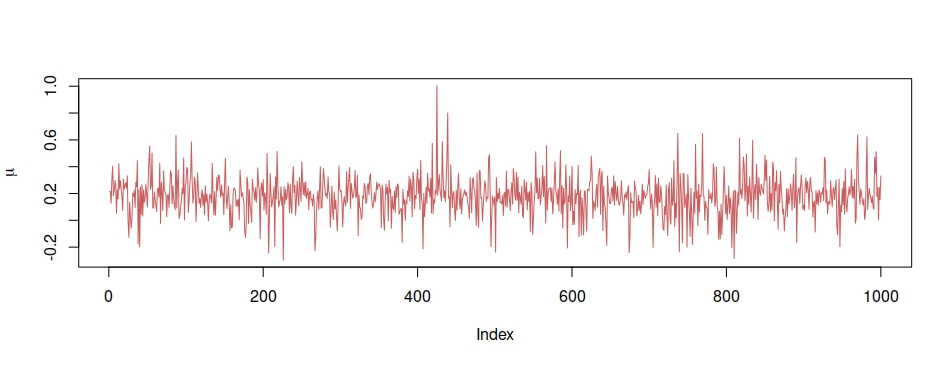
Posted in Books, pictures, R, Statistics with tags completion, cross validated, EM, expectation maximisation, Gibbs sampler, R on May 4, 2022 by xi'an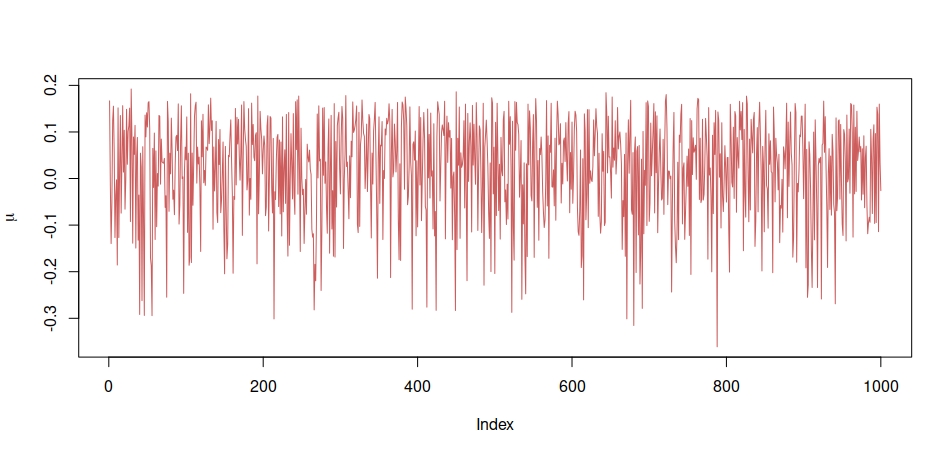 A question on X validated about EM steps for a truncated Normal mixture led me to ponder whether or not a more ambitious completion [more ambitious than the standard component allocation] was appropriate. Namely, if the mixture is truncated to the interval (a,b), with an observed sample x of size n, this sample could be augmented into an untrucated sample y by latent samples over the complement of (a,b), with random sizes corresponding to the probabilities of falling within (-∞,a), (a,b), and (b,∞). In other words, y is made of three parts, including x, with sizes N¹, n, N³, respectively, the vector (N¹, n, N³) being a trinomial M(N⁺,p) random variable and N⁺ an extra unknown in the model. Assuming a (pseudo-) conjugate prior, an approximate Gibbs sampler can be run (by ignoring the dependence of p on the mixture parameters!). I did not go as far as implementing the idea for the mixture, but had a quick try for a simple truncated Normal. And did not spot any explosive behaviour in N⁺, which is what I was worried about. Of course, this is mostly anecdotal since the completion does not bring a significant improvement in coding or convergence (the plots corresponds to 10⁴ simulations, for a sample of size n=400).
A question on X validated about EM steps for a truncated Normal mixture led me to ponder whether or not a more ambitious completion [more ambitious than the standard component allocation] was appropriate. Namely, if the mixture is truncated to the interval (a,b), with an observed sample x of size n, this sample could be augmented into an untrucated sample y by latent samples over the complement of (a,b), with random sizes corresponding to the probabilities of falling within (-∞,a), (a,b), and (b,∞). In other words, y is made of three parts, including x, with sizes N¹, n, N³, respectively, the vector (N¹, n, N³) being a trinomial M(N⁺,p) random variable and N⁺ an extra unknown in the model. Assuming a (pseudo-) conjugate prior, an approximate Gibbs sampler can be run (by ignoring the dependence of p on the mixture parameters!). I did not go as far as implementing the idea for the mixture, but had a quick try for a simple truncated Normal. And did not spot any explosive behaviour in N⁺, which is what I was worried about. Of course, this is mostly anecdotal since the completion does not bring a significant improvement in coding or convergence (the plots corresponds to 10⁴ simulations, for a sample of size n=400).
efficiency of normalising over discrete parameters
Posted in Statistics with tags arXiv, Gibbs sampler, Hamiltonian Monte Carlo, JAGS, latent variable models, marginalisation, MCMC, mixtures of distributions, Monte Carlo experiment, STAN on May 1, 2022 by xi'an Yesterday, I noticed a new arXival entitled Investigating the efficiency of marginalising over discrete parameters in Bayesian computations written by Wen Wang and coauthors. The paper is actually comparing the simulation of a Gibbs sampler with an Hamiltonian Monte Carlo approach on Gaussian mixtures, when including and excluding latent variables, respectively. The authors missed the opposite marginalisation when the parameters are integrated.
Yesterday, I noticed a new arXival entitled Investigating the efficiency of marginalising over discrete parameters in Bayesian computations written by Wen Wang and coauthors. The paper is actually comparing the simulation of a Gibbs sampler with an Hamiltonian Monte Carlo approach on Gaussian mixtures, when including and excluding latent variables, respectively. The authors missed the opposite marginalisation when the parameters are integrated.
While marginalisation requires substantial mathematical effort, folk wisdom in the Stan community suggests that fitting models with marginalisation is more efficient than using Gibbs sampling.
The comparison is purely experimental, though, which means it depends on the simulated data, the sample size, the prior selection, and of course the chosen algorithms. It also involves the [mostly] automated [off-the-shelf] choices made in the adopted software, JAGS and Stan. The outcome is only evaluated through ESS and the (old) R statistic. Which all depend on the parameterisation. But evacuates the label switching problem by imposing an ordering on the Gaussian means, which may have a different impact on marginalised and unmarginalised models. All in all, there is not much one can conclude about this experiment since the parameter values beyond the simulated data seem to impact the performances much more than the type of algorithm one implements.
mixed feelings
Posted in Books, Kids, Statistics with tags cross validated, disjoint support, EM algorithm, Gibbs sampler, mixtures of distributions on September 9, 2021 by xi'an Two recent questions on X validated about mixtures:
Two recent questions on X validated about mixtures:
- One on the potential negative explosion of the E function in the EM algorithm for a mixture of components with different supports: “I was hoping to use the EM algorithm to fit a mixture model in which the mixture components can have differing support. I’ve run into a problem during the M step because the expected log-likelihood can be [minus] infinite” Which mistake is based on a confusion between the current parameter estimate and the free parameter to optimise.
- Another one on the Gibbs sampler apparently failing for a two-component mixture with only the weights unknown, when the components are close to one another: “The algorithm works fine if σ is far from 1 but it does not work anymore for σ close to 1.” Which did not see a wide posterior as a possible posterior when both components are similar and hence delicate to distinguish from one another.
