integral priors for binomial regression
 Diego Salmerón and Juan Antonio Cano from Murcia, Spain (check the movie linked to the above photograph!), kindly included me in their recent integral prior paper, even though I mainly provided (constructive) criticism. The paper has just been arXived.
Diego Salmerón and Juan Antonio Cano from Murcia, Spain (check the movie linked to the above photograph!), kindly included me in their recent integral prior paper, even though I mainly provided (constructive) criticism. The paper has just been arXived.
A few years ago (2008 to be precise), we wrote together an integral prior paper, published in TEST, where we exploited the implicit equation defining those priors (Pérez and Berger, 2002), to construct a Markov chain providing simulations from both integral priors. This time, we consider the case of a binomial regression model and the problem of variable selection. The integral equations are similarly defined and a Markov chain can again be used to simulate from the integral priors. However, the difficulty therein follows from the regression structure, which makes selecting training datasets more elaborate, and whose posterior is not standard. Most fortunately, because the training dataset is exactly the right dimension, a re-parameterisation allows for a simulation of Bernoulli probabilities, provided a Jeffreys prior is used on those. (This obviously makes the “prior” dependent on the selected training dataset, but it should not overly impact the resulting inference.)

July 3, 2013 at 9:07 pm
A better way of asking the question (I always [?] get it in the end) is as follows.
How far from a “bad” prior (aka a prior that gives bad results) are the integral priors?
And, to answer my own question, I think that they’re quite far away, in the sense that you’re solving a well-posed problem (an integral equation of the second kind) to get the prior, so a “nearby” prior should be the solution of a “nearby” integral equation.
July 6, 2013 at 12:11 pm
Uh?! A prior that gives “bad” results?! Whazat?!
We define “objective” [testing] priors as a result of an information minimisation goal. The principle was laid by Pérez & Berger (2002) and we follow it in this less manageable setting of binomial regression.. I kind of like it for the reason that it allows for the ‘improper prior sin’ in testing, offering a way out or rather a way in for improper priors. The implementation issue is not part of this question.
Now, I agree with you [?] that we could have conducted experiments where we knew the “truth” and had the possibility of finding the error rate of a model selection principle based on integral priors. A nice proposal for a summer project.
July 2, 2013 at 11:30 pm
Could you also expand upon the procedure for generating training data? I’m clearly missing something. But in my mind training data begets pi^N, but step 2 requires pi^N, so I fail to see how to avoid the circular definition.
A different thing: drawing linearly independent columns isn’t, to my knowlege, trivial, especially in the big data context. Isn’t that part of why g-priors exist? (The X^T X but deals with the approximate colinearity) is there a similar trick here? I imagine drawing independent but almost colinear columns would be a bad thing…
July 6, 2013 at 12:17 pm
Training data: this is a sample with the smallest possible size so that the posterior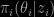 is proper. The posterior associated with the reference prior
is proper. The posterior associated with the reference prior 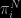 associated with model i. Which usually is improper. If you look at the four steps on page 5, each sounds clear enough to me. Mind that the reference prior
associated with model i. Which usually is improper. If you look at the four steps on page 5, each sounds clear enough to me. Mind that the reference prior 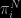 is an objective Bayes prior associated with the model $M_i$ per se, not the reference prior we are seeking. Maybe this explains for your confusion…
is an objective Bayes prior associated with the model $M_i$ per se, not the reference prior we are seeking. Maybe this explains for your confusion…
July 6, 2013 at 2:20 pm
Ah. Thanks!
July 6, 2013 at 1:12 pm
linear independence and near colinearity:I had not though of this problem indeed. In the paper, we pick the column indices at random. This is, I think, related with the overall debate as to whether or not we should condition on X (as opposed to modelling X as well). I am of the “condition on X” school.
July 6, 2013 at 2:19 pm
I think I’m of the “condition on X until it doesn’t work and then panic” school….
July 2, 2013 at 11:07 pm
I wonder if those integral equation could be solved numerically (at least for the dimensions of theta considered here (if I counted right that’s 5 and 12). I suspect it would be faster, cheaper, and more accurate than MCMC (although that’s not much of a bar to clear in moderate dimensions… ). They seem to just be second kind integral equations…
Then I’d probably stick the resulting approximate priors into INLA (but that’s personal preference :p)
Did you look at how the MC error upsets the balance ? (i.e. are the priors still neutral ) Because 10k chains will (if you’re lucky) give you 1 significant figure (maaaaybe 2).
(NB – I’ve only read the start and the end… Apologies if this was addressed in the middle (pp 5-10)… I’m getting to it presently)
A more general question: is this the sort of things scientists want? As opposed to designing objective priors on the whole of 2^X (X=set of covariates) and then leaping around the model space with gay abandon? Or is it more common/practical/useful to test given groupwise in/out hypotheses?
July 3, 2013 at 5:14 pm
Interesting suggestion about the numerical or even analytical resolution: I would think the answer is highly dependent on the model, although it may be that Beta/Bernoulli models can be handled rather easily… I am less sure I get the remark about MC(MC) error vs. numerical approximation error: it seems to apply every time MCMC is used!
July 3, 2013 at 5:17 pm
It’s a little different in this case. It is (moderately well) understood what MCMC does for posterior inference, but here you’re propagating this through another layer of inference machinery. So I guess it’s worth thinking about.
It’s probably just an awkward way of framing a “prior sensitivity” question. The prior that you’re actually using is a perturbation of a theoretically motivated prior, so it’s worth checking how good/bad that is.