ABC lectures [finale]
 The latest version of my ABC slides is on slideshare. To conclude with a pun, I took advantage of the newspaper clipping generator once pointed out by Andrew. (Note that nothing written in the above should be taken seriously.) On the serious side, I managed to cover most of the 300 slides (!) over the four courses and, thanks to the active attendance of several Wharton faculty, detailed PMC and ABC algorithms in ways I hope were accessible to the students. This course preparation was in any case quite helpful in the composition of a survey on ABC now with my co-authors.
The latest version of my ABC slides is on slideshare. To conclude with a pun, I took advantage of the newspaper clipping generator once pointed out by Andrew. (Note that nothing written in the above should be taken seriously.) On the serious side, I managed to cover most of the 300 slides (!) over the four courses and, thanks to the active attendance of several Wharton faculty, detailed PMC and ABC algorithms in ways I hope were accessible to the students. This course preparation was in any case quite helpful in the composition of a survey on ABC now with my co-authors.

January 26, 2012 at 12:12 am
[…] course starts next Thursday! (The core version of the slides is actually from the course I gave in Wharton more than a year ago.) […]
February 2, 2011 at 12:04 am
[…] are the slides of my talk—with some recycling from my slides at Wharton—at the workshop on Bayesian Inference for Latent Gaussian Models in Zurich next Saturday, in […]
December 17, 2010 at 12:04 am
[…] my Mac… I had been working for a few hours in my hotel room in Philadelphia, completing an ABC paper with Jean-Michel Marin and Robin Ryder. We had been running experiments in R with Jean-Michel over […]
November 7, 2010 at 12:12 am
[…] Following a comment by Mark Johnson on the ABC lectures, I read Murray, Ghahramani and MacKay’s “Doubly-intractable […]
November 5, 2010 at 5:09 am
[…] partly due to the warm welcome I received from the department, partly due to having to prepare this course on likelihood-free methods and rethinking about the fundamentals (the abc?!) of ABC (and partly to resisting buying Towers of […]
November 2, 2010 at 5:06 pm
This is wonderful site.
November 2, 2010 at 2:53 am
Perhaps “slows the execution speed down” is precisely the thing I’m worried about!
I also have a related question (if I may). It seems that ABC solves the “doubly intractable” problem of sampling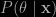 that Murray, Ghahramani and McKay raised in their 2006 paper. Of course this would be amazingly useful!
that Murray, Ghahramani and McKay raised in their 2006 paper. Of course this would be amazingly useful!
I’d like to use ABC on my problems in computational linguistics. Here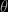 would be the parameters of the grammar I would like to estimate, and
would be the parameters of the grammar I would like to estimate, and  might be a sentence (a string of words). The problem is: there are a lot of sentences! Even given the “true” grammar parameters \theta, the probability of generating any particular sentence is astronomically small.
might be a sentence (a string of words). The problem is: there are a lot of sentences! Even given the “true” grammar parameters \theta, the probability of generating any particular sentence is astronomically small.
In the case of discrete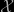 I don’t see how to define a useful tolerance region, and as far as I can tell, none of the methods you describe in your slides would help much either.
I don’t see how to define a useful tolerance region, and as far as I can tell, none of the methods you describe in your slides would help much either.
But even if it can’t solve my problems, ABC is still amazing. I’d be very pleased if I had a way to solve problems that Ghahramani and McKay had described as doubly intractable!
Thanks,
Mark
PS. For Probabilistic Context-Free Grammars we have MCMC algorithms (e.g., my paper), but of course real languages aren’t context-free! We have better models, but the partition functions become intractable as the models become more realistic.
November 2, 2010 at 9:09 am
Mark: The link to Murray, Ghahramani and McKay’ 2006 paper is quite relevant. First, because those doubly untractable distributions are a perfect setting for ABC. Second, because the solution of Moller, Pettit, Berthelsen and Reeves (2004, Biometrika) is a close alternative to ABC. Indeed, the core of the Moller et al.’ method is to simulate pseudo-data as in ABC, in order to cancel the untractable part of the likelihood. If one uses as target density on the auxiliary pseudo-data the indicator function used in ABC (assuming this results in a density on the pseudo-data), then we get rather close to ABC-MCMC! Of course, there still are differences in that
(a) the auxiliary variable method of Moller et al. still requires (the functional) part of the likelihood function to be available;
(b) the A in ABC-MCMC approach stands for approximative;
(c) the connection only works when considering a distance between the data and the pseudo-data, not when using summary statistics.
It would nonetheless be interesting to see a comparison between both approaches, for instance in a Potts model.
November 2, 2010 at 9:17 am
About finding tolerance in discrete setups: this also occurs with the probit/logit model where the data is made of 0’s and 1’s. In that case, you can use discrepancies like the Hamming distance in error-correcting codes…
November 1, 2010 at 12:07 pm
I’m really impressed and grateful for your books and blog entries — I’ve learned a lot from them. I’ve got a question about ABC (perhaps just a misunderstanding on my part). It seems to me that if the observation space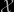 is huge, the ABC method might be intractable. For example, in your example on page 296 of your slides, what happens when
is huge, the ABC method might be intractable. For example, in your example on page 296 of your slides, what happens when  gets long? Doesn’t the probability of generating the observed state sequence drop exponentially in the length of
gets long? Doesn’t the probability of generating the observed state sequence drop exponentially in the length of  ?
?
If I’m understanding correctly, the ABC method is a bit reminiscent of the “shooting method” for solving boundary value ODE problems, except that here our “gun” is stochastic rather than deterministic!
November 1, 2010 at 1:32 pm
Mark: Thank you for your comments. The size of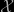 does not impact much the implementation of the ABC method, except that it slows execution speed down. The tolerance region being defined as a empirical quantile of the distance distribution. So the acceptance rate is fixed in advance. Of course, the larger the dataset, the harder it gets to discriminate between datasets. This is one reason why geneticists introduced summary statistics. By drastically reducing the dimension of the problem, they had a clear impact on the quality of the approximation.
does not impact much the implementation of the ABC method, except that it slows execution speed down. The tolerance region being defined as a empirical quantile of the distance distribution. So the acceptance rate is fixed in advance. Of course, the larger the dataset, the harder it gets to discriminate between datasets. This is one reason why geneticists introduced summary statistics. By drastically reducing the dimension of the problem, they had a clear impact on the quality of the approximation.