an ABC experiment
 In a cross-validated forum exchange, I used the code below to illustrate the working of an ABC algorithm:
In a cross-validated forum exchange, I used the code below to illustrate the working of an ABC algorithm:
#normal data with 100 observations
n=100
x=rnorm(n)
#observed summaries
sumx=c(median(x),mad(x))
#normal x gamma prior
priori=function(N){
return(cbind(rnorm(N,sd=10),
1/sqrt(rgamma(N,shape=2,scale=5))))
}
ABC=function(N,alpha=.05){
prior=priori(N) #reference table
#pseudo-data
summ=matrix(0,N,2)
for (i in 1:N){
xi=rnorm(n)*prior[i,2]+prior[i,1]
summ[i,]=c(median(xi),mad(xi)) #summaries
}
#normalisation factor for the distance
mads=c(mad(summ[,1]),mad(summ[,2]))
#distance
dist=(abs(sumx[1]-summ[,1])/mads[1])+
(abs(sumx[2]-summ[,2])/mads[2])
#selection
posterior=prior[dist<quantile(dist,alpha),]}
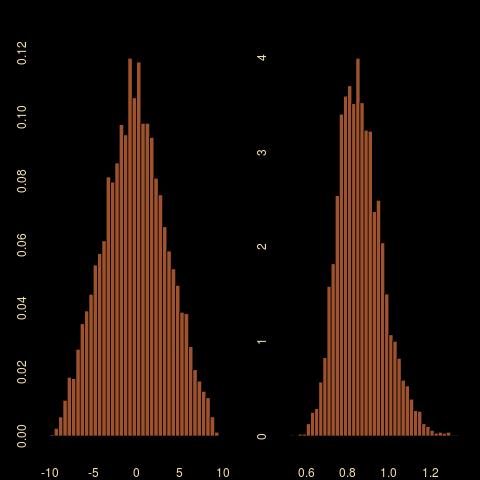
Hence I used the median and the mad as my summary statistics. And the outcome is rather surprising, for two reasons: the first one is that the posterior on the mean μ is much wider than when using the mean and the variance as summary statistics. This is not completely surprising in that the latter are sufficient, while the former are not. Still, the (-10,10) range on the mean is way larger… The second reason for surprise is that the true posterior distribution cannot be derived since the joint density of med and mad is unavailable.
 sample of size 5000: (top) ABC using mean and variance as summaries; (middle) ABC using median and mad as summaries; (bottom) Gibbs sampling, all based on 10⁶ simulations with the same 5% subsampling rate") After thinking about this for a while, I went back to my workbench to check the difference with using mean and variance. To my greater surprise, I found hardly any difference! Using the almost exact ABC with 10⁶ simulations and a 5% subsampling rate returns exactly the same outcome. (The first row above is for the sufficient statistics (mean,standard deviation) while the second row is for the (median,mad) pair.) Playing with the distance does not help. The genuine posterior output is quite different, as exposed on the last row of the above, using a basic Gibbs sampler since the posterior is not truly conjugate.
After thinking about this for a while, I went back to my workbench to check the difference with using mean and variance. To my greater surprise, I found hardly any difference! Using the almost exact ABC with 10⁶ simulations and a 5% subsampling rate returns exactly the same outcome. (The first row above is for the sufficient statistics (mean,standard deviation) while the second row is for the (median,mad) pair.) Playing with the distance does not help. The genuine posterior output is quite different, as exposed on the last row of the above, using a basic Gibbs sampler since the posterior is not truly conjugate.

December 5, 2014 at 4:06 am
I’m confirming the prior because the shape parameter must be bigger than 2 for the prior variance to be finite (if that matters).
December 5, 2014 at 4:03 am
Thank you for this example, Prof. Robert. I didn’t expect ABC to perform so poorly in such a simple case, in which we even have nice small dimensional sufficient statistics available to be used as summaries. I’ll recode it tomorrow. Your prior for the variance is IG(shape = 2, scale = 5)? (using this parameterization: http://en.wikipedia.org/wiki/Inverse-gamma_distribution#Probability_density_function)
November 24, 2014 at 4:07 pm
I agree with Dennis: Beaumont’s post-processing helps a lot in many cases (and in this one in particular)!
November 27, 2014 at 8:33 am
Thanks for those precisions. I actually find the correction “depressing” in that, without it, the ABC solution is rather poor. So what makes ABC work in practice (and in DIYABC in particular) is more the non-parametric part than the mere simulation part. It is nice at the statistical level to realise that the non-parametric regression does so well with so little, but depressing at the Monte Carlo level. In any case, those inputs will help me much in writing this survey I am completing.
November 24, 2014 at 2:41 pm
5% seems quite a high acceptance rate when there are so many simulations. Using 0.1% gives more sensible looking results for the scale parameter, but the location still has very large posterior variance. Regression post-processing would probably help. Alternatively an idea I’ve been looking at recently is to replace “mads” with “norm” where:
res=lm(summ~prior)$residuals
norm=apply(res, 2, sd)
(Also in the code the true parameter values are (0,1) rather than (3,2) as in the diagram.)
Anyway, interesting example!
November 24, 2014 at 4:02 pm
Thank you, Dennis! Sorry for the confusion with the graphs: the top one is based on 100 N(0,1) observations, while the comparative bottom on is for 5000 N(3,2²) observations. I agree that using 5% of the simulations is not necessary, although my experience is that decreasing the tolerance does not matter after a while. I will give it another check with .1% to see if my R code is to blame…
November 24, 2014 at 6:28 pm
After re-running the R code, I completely agree with this assessment that the mean does not get much better when moving to 0.1%. Presumably the impact of the very vague prior on the mean (when compared with a less vague prior on the variance). It is quite interesting that simulating first from the prior could have a long-term effect on the approximation. I wonder if there is a general lesson to learn from that. It makes me realise that the final value of the tolerance is a direct function of the prior distribution. Since it is taken as a quantile of the prior predictive distances to the data. Hence the afore-said impact…