Leave the Pima Indians alone!
“…our findings shall lead to us be critical of certain current practices. Specifically, most papers seem content with comparing some new algorithm with Gibbs sampling, on a few small datasets, such as the well-known Pima Indians diabetes dataset (8 covariates). But we shall see that, for such datasets, approaches that are even more basic than Gibbs sampling are actually hard to beat. In other words, datasets considered in the literature may be too toy-like to be used as a relevant benchmark. On the other hand, if ones considers larger datasets (with say 100 covariates), then not so many approaches seem to remain competitive” (p.1)

Nicolas Chopin and James Ridgway (CREST, Paris) completed and arXived a paper they had “threatened” to publish for a while now, namely why using the Pima Indian R logistic or probit regression benchmark for checking a computational algorithm is not such a great idea! Given that I am definitely guilty of such a sin (in papers not reported in the survey), I was quite eager to read the reasons why! Beyond the debate on the worth of such a benchmark, the paper considers a wider perspective as to how Bayesian computation algorithms should be compared, including the murky waters of CPU time versus designer or programmer time. Which plays against most MCMC sampler.
As a first entry, Nicolas and James point out that the MAP can be derived by standard a Newton-Raphson algorithm when the prior is Gaussian, and even when the prior is Cauchy as it seems most datasets allow for Newton-Raphson convergence. As well as the Hessian. We actually took advantage of this property in our comparison of evidence approximations published in the Festschrift for Jim Berger. Where we also noticed the awesome performances of an importance sampler based on the Gaussian or Laplace approximation. The authors call this proposal their gold standard. Because they also find it hard to beat. They also pursue this approximation to its logical (?) end by proposing an evidence approximation based on the above and Chib’s formula. Two close approximations are provided by INLA for posterior marginals and by a Laplace-EM for a Cauchy prior. Unsurprisingly, the expectation-propagation (EP) approach is also implemented. What EP lacks in theoretical backup, it seems to recover in sheer precision (in the examples analysed in the paper). And unsurprisingly as well the paper includes a randomised quasi-Monte Carlo version of the Gaussian importance sampler. (The authors report that “the improvement brought by RQMC varies strongly across datasets” without elaborating for the reasons behind this variability. They also do not report the CPU time of the IS-QMC, maybe identical to the one for the regular importance sampling.) Maybe more surprising is the absence of a nested sampling version.
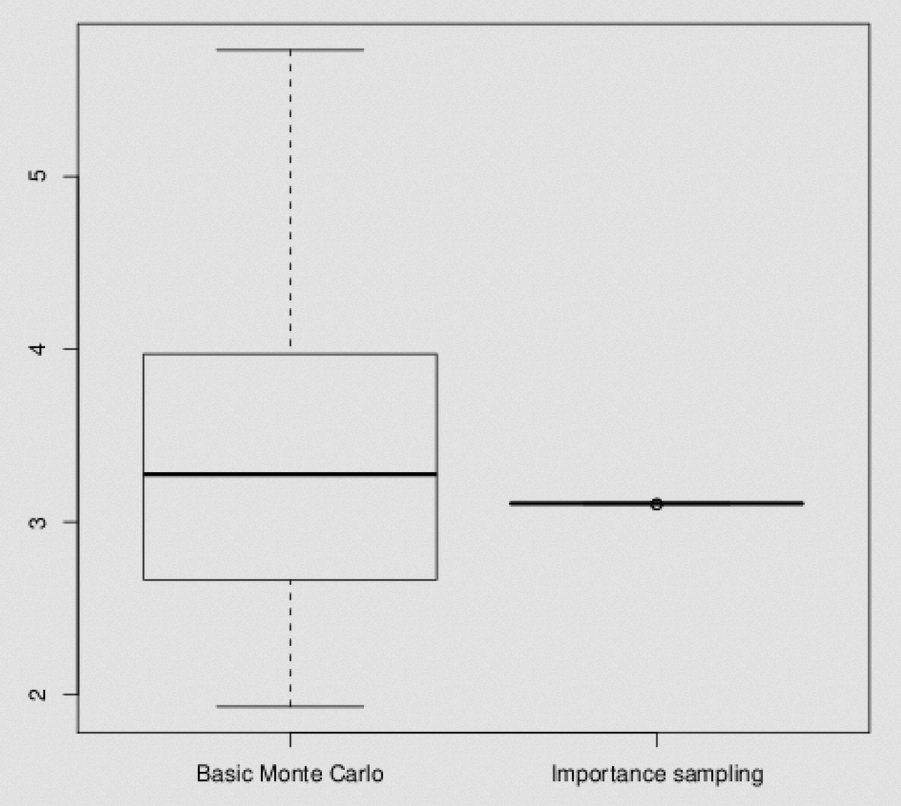 In the Markov chain Monte Carlo solutions, Nicolas and James compare Gibbs, Metropolis-Hastings, Hamiltonian Monte Carlo, and NUTS. Plus a tempering SMC, All of which are outperformed by importance sampling for small enough datasets. But get back to competing grounds for large enough ones, since importance sampling then fails.
In the Markov chain Monte Carlo solutions, Nicolas and James compare Gibbs, Metropolis-Hastings, Hamiltonian Monte Carlo, and NUTS. Plus a tempering SMC, All of which are outperformed by importance sampling for small enough datasets. But get back to competing grounds for large enough ones, since importance sampling then fails.
“…let’s all refrain from now on from using datasets and models that are too simple to serve as a reasonable benchmark.” (p.25)
This is a very nice su rvey on the theme of binary data (more than on the comparison of algorithms in that the authors do not really take into account design and complexity, but resort to MSEs versus CPus). I however do not agree with their overall message to leave the Pima Indians alone. Or at least not for the reason provided therein, namely that faster and more accurate approximations methods are available and cannot be beaten. Benchmarks always have the limitation of “what you get is what you see”, i.e., the output associated with a single dataset that only has that many idiosyncrasies. Plus, the closeness to a perfect normal posterior makes the logistic posterior too regular to pause a real challenge (even though MCMC algorithms are as usual slower than iid sampling). But having faster and more precise resolutions should on the opposite be cause for cheers, as this provides a reference value, a golden standard, to check against. In a sense, for every Monte Carlo method, there is a much better answer, namely the exact value of the integral or of the optimum! And one is hardly aiming at a more precise inference for the benchmark itself: those Pima Indians [whose actual name is Akimel O’odham] with diabetes involved in the original study are definitely beyond help from statisticians and the model is unlikely to carry out to current populations. When the goal is to compare methods, as in our 2009 paper for Jim Berger’s 60th birthday, what matters is relative speed and relative ease of implementation (besides the obvious convergence to the proper target). In that sense bigger and larger is not always relevant. Unless one tackles really big or really large datasets, for which there is neither benchmark method nor reference value.
rvey on the theme of binary data (more than on the comparison of algorithms in that the authors do not really take into account design and complexity, but resort to MSEs versus CPus). I however do not agree with their overall message to leave the Pima Indians alone. Or at least not for the reason provided therein, namely that faster and more accurate approximations methods are available and cannot be beaten. Benchmarks always have the limitation of “what you get is what you see”, i.e., the output associated with a single dataset that only has that many idiosyncrasies. Plus, the closeness to a perfect normal posterior makes the logistic posterior too regular to pause a real challenge (even though MCMC algorithms are as usual slower than iid sampling). But having faster and more precise resolutions should on the opposite be cause for cheers, as this provides a reference value, a golden standard, to check against. In a sense, for every Monte Carlo method, there is a much better answer, namely the exact value of the integral or of the optimum! And one is hardly aiming at a more precise inference for the benchmark itself: those Pima Indians [whose actual name is Akimel O’odham] with diabetes involved in the original study are definitely beyond help from statisticians and the model is unlikely to carry out to current populations. When the goal is to compare methods, as in our 2009 paper for Jim Berger’s 60th birthday, what matters is relative speed and relative ease of implementation (besides the obvious convergence to the proper target). In that sense bigger and larger is not always relevant. Unless one tackles really big or really large datasets, for which there is neither benchmark method nor reference value.

August 9, 2019 at 9:00 pm
[…] a comparison a Polya-Urn sampler with several HMC samplers for a logistic target (not involving the Pima Indian dataset!). The larger the lag L the more accurate the bound. But the larger the lag the more expensive the […]
July 11, 2016 at 4:45 pm
[…] but xian changed it to “Leave *the* Pima Indians alone…” when discussing it on his blog. Any opinion on whether it does sound better with […]
September 4, 2015 at 11:09 am
[…] xian changed it to “Leave *the* Pima Indians alone…” when discussing it on his blog. Any opinion on whether it does sound better with […]
September 6, 2015 at 7:16 pm
Sorry, Nicolas, I did not mean to take upon your English, I simply transcribed your title and inadvertently added the “the”… I would intuitively keep the “the”, but I know nothing, as we all know!
July 16, 2015 at 3:55 pm
I like this paper a lot!
It also connects with your comments about the MCMC for “Tall Data” paper the other week. For tall data (ie big n, small p), Laplace approximations are linear in n and are well and truly in their asymptotic domain of applicability. So it’s test cases where this doesn’t work (i.e. not logistic regression!) that the method is interesting for.
(Note that all the linear algebra required is parallelisable)
There’s still a role for logistic regression examples in this regime, but really only in the “sanity checking” regime.