Monte Carlo Markov chains

“Two major avenues are available for the assignment of probabilities. One is based on the repetition of the experiments a large number of times under the same conditions, and goes under the name of the frequentist or classical method. The other is based on a more theoretical knowledge of the experiment, but without the experimental requirement, and is referred to as the Bayesian approach.”
“The Bayesian probability is assigned based on a quantitative understanding of the nature of the experiment, and in accord with the Kolmogorov axioms. It is sometimes referred to as empirical probability, in recognition of the fact that sometimes the probability of an event is assigned based upon a practical knowledge of the experiment, although without the classical requirement of repeating the experiment for a large number of times. This method is named after the Rev. Thomas Bayes, who pioneered the development of the theory of probability.”
“The likelihood P(B/A) represents the probability of making the measurement B given that the model A is a correct description of the experiment.”
“…a uniform distribution is normally the logical assumption in the absence of other information.”
“The Gaussian distribution can be considered as a special case of the binomial, when the number of tries is sufficiently large.”
“This clearly does not mean that the Poisson distribution has no variance—in that case, it would not be a random variable!”
“The method of moments therefore returns unbiased estimates for the mean and variance of every distribution in the case of a large number of measurements.”
“The great advantage of the Gibbs sampler is the fact that the acceptance is 100 %, since there is no rejection of candidates for the Markov chain, unlike the case of the Metropolis–Hastings algorithm.”
Let me then point out (or just whine about!) the book using “statistical independence” for plain independence, the use of / rather than Jeffreys’ | for conditioning (and sometimes forgetting \ in some LaTeX formulas), the confusion between events and random variables, esp. when computing the posterior distribution, between models and parameter values, the reliance on discrete probability for continuous settings, as in the Markov chain chapter, confusing density and probability, using Mendel’s pea data without mentioning the unlikely fit to the expected values (or, as put more subtly by Fisher (1936), “the data of most, if not all, of the experiments have been falsified so as to agree closely with Mendel’s expectations”), presenting Fisher’s and Anderson’s Iris data [a motive for rejection when George was JASA editor!] as a “a new classic experiment”, mentioning Pearson but not Lee for the data in the 1903 Biometrika paper “On the laws of inheritance in man” (and woman!), and not accounting for the discrete nature of this data in the linear regression chapter, the three page derivation of the Gaussian distribution from a Taylor expansion of the Binomial pmf obtained by differentiating in the integer argument, spending endless pages on deriving standard properties of classical distributions, this appalling mess of adding over the conditioning atoms with no normalisation in a Poisson experiment
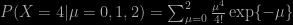
botching the proof of the CLT, which is treated before the Law of Large Numbers, restricting maximum likelihood estimation to the Gaussian and Poisson cases and muddling its meaning by discussing unbiasedness, confusing a drifted Poisson random variable with a drift on its parameter, as well as using the pmf of the Poisson to define an area under the curve (Fig. 5.2), sweeping the improperty of a constant prior under the carpet, defining a null hypothesis as a range of values for a summary statistic, no mention of Bayesian perspectives in the hypothesis testing, model comparison, and regression chapters, having one-dimensional case chapters followed by two-dimensional case chapters, reducing model comparison to the use of the Kolmogorov-Smirnov test, processing bootstrap and jackknife in the Monte Carlo chapter without a mention of importance sampling, stating recurrence results without assuming irreducibility, motivating MCMC by the intractability of the evidence, resorting to the term link to designate the current value of a Markov chain, incorporating the need for a prior distribution in a terrible description of the Metropolis-Hastings algorithm, including a discrete proof for its stationarity, spending many pages on early 1990’s MCMC convergence tests rather than discussing the adaptive scaling of proposal distributions, the inclusion of numerical tables [in a 2017 book] and turning Bayes (1763) into Bayes and Price (1763), or Student (1908) into Gosset (1908).
[Usual disclaimer about potential self-plagiarism: this post or an edited version of it could possibly appear later in my Books Review section in CHANCE. Unlikely, though!]

May 12, 2020 at 5:44 pm
Merci pour ces savoureux extraits. Nous avons bien ri.
May 12, 2020 at 5:46 pm
!!!
May 12, 2020 at 1:37 am
May I ask what is so wrong with “motivating MCMC by the intractability of the evidence”?
May 12, 2020 at 3:43 pm
The way I interpret (or translate into French) this sentence is that a missing normalising constant in a target density is the primary reason for introducing MCMC methods in the Monte Carlo universe. Actually, most simulation methods operate without heeding this constant. And conversely the most appropriate methods for approximating the evidence are not MCMC based (excepting Chib’s method).
May 12, 2020 at 3:48 pm
Right. This makes sense.