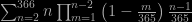A zorbing puzzle from the Riddler: cover the plane with four non-intersecting disks of radius one towards getting the highest probability (under the standard bivariate Normal distribution).
A zorbing puzzle from the Riddler: cover the plane with four non-intersecting disks of radius one towards getting the highest probability (under the standard bivariate Normal distribution).
As I could not see a simple connection between the disks and the standard Normal, beyond the probability of a disk being given by a non-central chi-square cdf (with two degrees of freedom), I (once again) tried a random search by simulated annealing, which ended up with a configuration like the above, never above 0.777 using a pedestrian R code like
for(t in 1:1e6){# move the disk centres
Ap=A+vemp*rnorm(2)
Bp=B+vemp*rnorm(2)
while(dist(rbind(Ap,Bp))<2)Bp=B+vemp*rnorm(2)
Cp=C+vemp*rnorm(2)
while(min(dist(rbind(Ap,Bp,Cp)))<2)Cp=C+vemp*rnorm(2)
Dp=D+vemp*rnorm(2)
while(min(dist(rbind(Ap,Bp,Cp,Dp)))<2)Dp=D+vemp*rnorm(2)
#coverage probability
pp=pchisq(1,df=2,ncp=Ap%*%Ap)+pchisq(1,df=2,ncp=Bp%*%Bp)+
pchisq(1,df=2,ncp=Cp%*%Cp)+pchisq(1,df=2,ncp=Dp%*%Dp)
#simulated annealing step
if(log(runif(1))<(pp-p)/sqrt(temp)){
A=Bp;B=Cp;C=Dp;D=Ap;p=pp
if (sol$val<p) sol=list(val=pp,pos=rbind(A,B,C,D))}
temp=temp*.9999}
I also tried a simpler configuration where all disk centres were equidistant from a reference centre, but this led to a lower “optimal” probability. I was looking forward the discussion of the puzzle, to discover if anything less brute-force was possible! But there was no deeper argument there beyond the elimination of other “natural” configurations (and missing the non-central χ² connection!). Among these options, having two disks tangent at (0,0) were optimal. But the illustration was much nicer:


 A
A  An easy
An easy