This week, Le Monde offers not one but three related puzzles:
- Is it possible to label the twelve edges of a cube by consecutive numbers such that the sum of the edge numbers at any of the eight nodes is constant?
- Is it possible to label the eight nodes of a cube by consecutive numbers such that the sums of the node numbers over the edges are all different?
- It possible to label the twelve edges of a cube by consecutive numbers except for two edges where the difference is two such that the sum of the edge numbers at any of the eight nodes is constant?
A first comment is that the lowest number amont the eight, twelve or fourteen can always be taken equal to zero. The problems are location invariant.
For the first problem, since the edges are labeled from 0 to 11, the sum of the numbers is 1+…+11 = 11×12/2. The sum of the values over all nodes is therefore 11×12, which should also be equal to 8xs, s being the constant sum at each node. Since 11×12 cannot be divided by 8, this is impossible.
For the second problem, were there a solution, an R resolution would be
edges=rbind(c(1,1,1,2,2,3,3,4,5,5,6,7),c(2,4,5,3,6,4,7,8,6,8,7,8))
le=11
while (le<12){
node=sample(0:7)
le=length(unique(node[edges[1,]]+node[edges[2,]]))}
However, the R code does not produce an answer after a long wait, implying this is not possible.
For the third problem, there is a jump in the sequence of edge numbers at a>-1, then again at 10>b>a. Therefore the sum of the edge numbers is 11×6 + (b-a)+2x(11-b), i.e 88-a-b, which should be divisible by 4 when all the nodes have the same value. This occurs when a+b is divisible by 4, e.g. when a=6, b=10. This choice leads to the R code
b=sample(3:9,1)
a=sample(c(4-b,8-b,12-b),1)
while ((a<0)||(a>b)) a=sample(c(4-b,8-b,12-b),1)
newedge=sample(c(0:a,(a+2):(b+1),(b+3):13))
le=NULL
for (i in 1:8)
le=c(le,sum(newedge[((edges[1,]!=i)*(edges[2,]!=i))==0]))
while (length(unique(le))>1){
b=sample(3:9,1)
a=sample(c(4-b,8-b,12-b),1)
while ((a<0)||(a>b)) a=sample(c(4-b,8-b,12-b),1)
newedge=sample(c(0:a,(a+2):(b+1),(b+3):13))
le=NULL
for (i in 1:8)
le=c(le,sum(newedge[((edges[1,]!=i)*(edges[2,]!=i))==0]))
}
which produces a positive outcome
> le
[1] 20 20 20 20 20 20 20 20
> a
[1] 0
> b
[1] 8
> newedge
[1] 9 8 3 7 4 0 13 12 11 6 5 2
 A first graph in Le Monde about the impact of the recent tax changes on French households as a percentage of net income with negative values at both ends, except for a small spike at about 10% and another one for the upper 1%, presumably linked with the end of the fortune tax (ISF).
A first graph in Le Monde about the impact of the recent tax changes on French households as a percentage of net income with negative values at both ends, except for a small spike at about 10% and another one for the upper 1%, presumably linked with the end of the fortune tax (ISF). A second one showing incompressible expenses by income category, with poorest households facing a large constraint on lodging, missing the fraction due to taxes. Unless the percentage is computed after tax.
A second one showing incompressible expenses by income category, with poorest households facing a large constraint on lodging, missing the fraction due to taxes. Unless the percentage is computed after tax. A last and amazing one detailing the median monthly income per socio-professional category, not because of the obvious typo on the blue collar median 1994!, but more fundamentally because retirees have a median income in the upper part of the range. (This may be true in most developed countries, I was just unaware of this imbalance.)
A last and amazing one detailing the median monthly income per socio-professional category, not because of the obvious typo on the blue collar median 1994!, but more fundamentally because retirees have a median income in the upper part of the range. (This may be true in most developed countries, I was just unaware of this imbalance.)
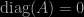 , does there exist a triplet (i,j,k) such that
, does there exist a triplet (i,j,k) such that

 satisfies
satisfies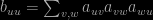
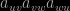 is different from zero. Here is the R code:
is different from zero. Here is the R code: