 My colleague from the Université d’Orléans, Didier Chauveau, has just published on CRAN a new R package called EntropyMCMC, which contains convergence assessment tools for MCMC algorithms, based on non-parametric estimates of the Kullback-Leibler divergence between current distribution and target. (A while ago, quite a while ago!, we actually collaborated with a few others on the Springer-Verlag Lecture Note #135 Discretization and MCMC convergence assessments.) This follows from a series of papers by Didier Chauveau and Pierre Vandekerkhove that started with a nearest neighbour entropy estimate. The evaluation of this entropy is based on N iid (parallel) chains, which involves a parallel implementation. While the missing normalising constant is overwhelmingly unknown, the authors this is not a major issue “since we are mostly interested in the stabilization” of the entropy distance. Or in the comparison of two MCMC algorithms. [Disclaimer: I have not experimented with the package so far, hence cannot vouch for its performances over large dimensions or problematic targets, but would as usual welcome comments and feedback on readers’ experiences.]
My colleague from the Université d’Orléans, Didier Chauveau, has just published on CRAN a new R package called EntropyMCMC, which contains convergence assessment tools for MCMC algorithms, based on non-parametric estimates of the Kullback-Leibler divergence between current distribution and target. (A while ago, quite a while ago!, we actually collaborated with a few others on the Springer-Verlag Lecture Note #135 Discretization and MCMC convergence assessments.) This follows from a series of papers by Didier Chauveau and Pierre Vandekerkhove that started with a nearest neighbour entropy estimate. The evaluation of this entropy is based on N iid (parallel) chains, which involves a parallel implementation. While the missing normalising constant is overwhelmingly unknown, the authors this is not a major issue “since we are mostly interested in the stabilization” of the entropy distance. Or in the comparison of two MCMC algorithms. [Disclaimer: I have not experimented with the package so far, hence cannot vouch for its performances over large dimensions or problematic targets, but would as usual welcome comments and feedback on readers’ experiences.]
Archive for Lecture Notes in Statistics
EntropyMCMC [R package]
Posted in Statistics with tags convergence assessment, CRAN, discretization, entropy, EntropyMCMC, Lecture Notes in Statistics, MCMC, MCMC convergence, Monte Carlo Statistical Methods, R package, Springer-Verlag, Université d'Orléans, untractable normalizing constant on March 26, 2019 by xi'anComputing evidence
Posted in Books, R, Statistics with tags Bayesian model choice, evidence, harmonic mean estimator, latent variable, Lecture Notes in Statistics, MCMC, mixed effect models, path sampling, prior projection, simulation, unbiasedness on November 29, 2010 by xi'an") The book Random effects and latent variable model selection, edited by David Dunson in 2008 as a Springer Lecture Note. contains several chapters dealing with evidence approximation in mixed effect models. (Incidentally, I would be interested in the story behind the Lecture Note as I found no explanation in the backcover or in the preface. Some chapters but not all refer to a SAMSI workshop on model uncertainty…) The final chapter written by Joyee Ghosh and David Dunson (similar to a corresponding paper in JCGS) contains in particular the interesting identity that the Bayes factor opposing model h to model h-1 can be unbiasedly approximated by (the average of the terms)
The book Random effects and latent variable model selection, edited by David Dunson in 2008 as a Springer Lecture Note. contains several chapters dealing with evidence approximation in mixed effect models. (Incidentally, I would be interested in the story behind the Lecture Note as I found no explanation in the backcover or in the preface. Some chapters but not all refer to a SAMSI workshop on model uncertainty…) The final chapter written by Joyee Ghosh and David Dunson (similar to a corresponding paper in JCGS) contains in particular the interesting identity that the Bayes factor opposing model h to model h-1 can be unbiasedly approximated by (the average of the terms)
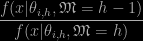
when
is the model index,
- the
‘s are simulated from the posterior under model h,
- the model
only considers the h-1 first components of
- the prior under model h-1 is the projection of the prior under model h. (Note that this marginalisation is not the projection used in Bayesian Core.)
