 Yesterday came out on arXiv a joint paper by Pierre Jacob, Lawrence Murray, Chris Holmes and myself, Better together? Statistical learning in models made of modules, paper that was conceived during the MCMski meeting in Chamonix, 2014! Indeed it is mostly due to Martyn Plummer‘s talk at this meeting about the cut issue that we started to work on this topic at the fringes of the [standard] Bayesian world. Fringes because a standard Bayesian approach to the problem would always lead to use the entire dataset and the entire model to infer about a parameter of interest. [Disclaimer: the use of the very slogan of the anti-secessionists during the Scottish Independence Referendum of 2014 in our title is by no means a measure of support of their position!] Comments and suggested applications most welcomed!
Yesterday came out on arXiv a joint paper by Pierre Jacob, Lawrence Murray, Chris Holmes and myself, Better together? Statistical learning in models made of modules, paper that was conceived during the MCMski meeting in Chamonix, 2014! Indeed it is mostly due to Martyn Plummer‘s talk at this meeting about the cut issue that we started to work on this topic at the fringes of the [standard] Bayesian world. Fringes because a standard Bayesian approach to the problem would always lead to use the entire dataset and the entire model to infer about a parameter of interest. [Disclaimer: the use of the very slogan of the anti-secessionists during the Scottish Independence Referendum of 2014 in our title is by no means a measure of support of their position!] Comments and suggested applications most welcomed!
![]() The setting of the paper is inspired by realistic situations where a model is made of several modules, connected within a graphical model that represents the statistical dependencies, each relating to a specific data modality. In a standard Bayesian analysis, given data, a conventional statistical update then allows for coherent uncertainty quantification and information propagation through and across the modules. However, misspecification of or even massive uncertainty about any module in the graph can contaminate the estimate and update of parameters of other modules, often in unpredictable ways. Particularly so when certain modules are trusted more than others. Hence the appearance of cut models, where practitioners prefer skipping the full model and limit the information propagation between these modules, for example by restricting propagation to only one direction along the edges of the graph. (Which is sometimes represented as a diode on the edge.) The paper investigates in which situations and under which formalism such modular approaches can outperform the full model approach in misspecified settings. By developing the appropriate decision-theoretic framework. Meaning we can choose between [several] modular and full-model approaches.
The setting of the paper is inspired by realistic situations where a model is made of several modules, connected within a graphical model that represents the statistical dependencies, each relating to a specific data modality. In a standard Bayesian analysis, given data, a conventional statistical update then allows for coherent uncertainty quantification and information propagation through and across the modules. However, misspecification of or even massive uncertainty about any module in the graph can contaminate the estimate and update of parameters of other modules, often in unpredictable ways. Particularly so when certain modules are trusted more than others. Hence the appearance of cut models, where practitioners prefer skipping the full model and limit the information propagation between these modules, for example by restricting propagation to only one direction along the edges of the graph. (Which is sometimes represented as a diode on the edge.) The paper investigates in which situations and under which formalism such modular approaches can outperform the full model approach in misspecified settings. By developing the appropriate decision-theoretic framework. Meaning we can choose between [several] modular and full-model approaches.


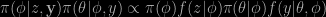

{kind=link}