 As I was travelling to Coventry yesterday, I spotted this fellow passenger on the train from Birmingham with a Valencia 9 bag, and a chat with him. It was a pure chance encounter as he was not attending our summer school, but continued down the line. (These bags are quite sturdy and I kept mine until a zipper broke.)
As I was travelling to Coventry yesterday, I spotted this fellow passenger on the train from Birmingham with a Valencia 9 bag, and a chat with him. It was a pure chance encounter as he was not attending our summer school, but continued down the line. (These bags are quite sturdy and I kept mine until a zipper broke.)
Archive for Valencia 9
chance meeting
Posted in Statistics with tags backpack, Birmingham, CHANCE, CRiSM, National Rail, sent to Coventry, train, University of Warwick, Valencia 9, Valencia conferences on July 10, 2018 by xi'anParticle learning [rejoinder]
Posted in R, Statistics, University life with tags Bayesian Analysis, convergence diagnostics, degeneracy, discussions, MCMC, mixtures, Monte Carlo Statistical Methods, particle learning, sequential Monte Carlo, Statistical Science, Valencia 9 on November 10, 2010 by xi'anFollowing the posting on arXiv of the Statistical Science paper of Carvalho et al., and the publication by the same authors in Bayesian Analysis of Particle Learning for general mixtures I noticed on Hedibert Lopes’ website his rejoinder to the discussion of his Valencia 9 paper has been posted. Since the discussion involved several points made by members of the CREST statistics lab (and covered the mixture paper as much as the Valencia 9 paper), I was quite eager to read Hedie’s reply. Unsurprisingly, this rejoinder is however unlikely to modify my reservations about particle learning. The following is a detailed examination of the arguments found in the rejoinder but requires a preliminary reading of the above papers as well as our discussion.. Continue reading
Continue reading
Parallel processing of independent Metropolis-Hastings algorithms
Posted in R, Statistics, University life with tags Chris Holmes, cloud computing, GPU, importance sampling, JSM 2010, Metropolis-Hastings, parallelisation, Rao-Blackwellisation, Valencia 9 on October 12, 2010 by xi'anWith Pierre Jacob, my PhD student, and Murray Smith, from National Institute of Water and Atmospheric Research, Wellington, who actually started us on this project at the last and latest Valencia meeting, we have completed a paper on using parallel computing in independent Metropolis-Hastings algorithms. The paper is arXived and the abstract goes as follows:
In this paper, we consider the implications of the fact that parallel raw-power can be exploited by a generic Metropolis–Hastings algorithm if the proposed values are independent. In particular, we present improvements to the independent Metropolis–Hastings algorithm that significantly decrease the variance of any estimator derived from the MCMC output, for a null computing cost since those improvements are based on a fixed number of target density evaluations. Furthermore, the techniques developed in this paper do not jeopardize the Markovian convergence properties of the algorithm, since they are based on the Rao–Blackwell principles of Gelfand and Smith (1990), already exploited in Casella and Robert 91996), Atchadé and Perron (2005) and Douc and Robert (2010). We illustrate those improvement both on a toy normal example and on a classical probit regression model but insist on the fact that they are universally applicable.
I am quite excited about the results in this paper, which took advantage of (a) older works of mine on Rao-Blackwellisation, (b) Murray’s interests in costly likelihoods, and (c) our mutual excitement when hearing about GPU parallel possibilities from Chris Holmes’ talk in Valencia. (As well as directions drafted in an exciting session in Vancouver!) The (free) gains over standard independent Metropolis-Hastings estimates are equivalent to using importance sampling gains, while keeping the Markov structure of the original chain. Given that 100 or more parallel threads can be enhanced from current GPU cards, this is clearly a field with much potential! The graph below
 gives the variance improvements brought by three Rao-Blackwell estimates taking advantage of parallelisation over the initial MCMC estimate (first entry) with the importance sampling estimate (last entry) using only 10 parallel threads.
gives the variance improvements brought by three Rao-Blackwell estimates taking advantage of parallelisation over the initial MCMC estimate (first entry) with the importance sampling estimate (last entry) using only 10 parallel threads.
Multidimension bridge sampling (CoRe in CiRM [5])
Posted in Books, R, Statistics, University life with tags Bayesian Core, Benidorm, bridge sampling, CIRM, poster, Valencia 9 on July 14, 2010 by xi'an Since Bayes factor approximation is one of my areas of interest, I was intrigued by Xiao-Li Meng’s comments during my poster in Benidorm that I was using the “wrong” bridge sampling estimator when trying to bridge two models of different dimensions, based on the completion (for
Since Bayes factor approximation is one of my areas of interest, I was intrigued by Xiao-Li Meng’s comments during my poster in Benidorm that I was using the “wrong” bridge sampling estimator when trying to bridge two models of different dimensions, based on the completion (for 


When revising the normal chapter of Bayesian Core, here in CiRM, I thus went back to Xiao-Li’s papers on the topic to try to fathom what the “true” bridge sampling was in that case. In Meng and Schilling (2002, JASA), I found the following indication, “when estimating the ratio of normalizing constants with different dimensions, a good strategy is to bridge each density with a good approximation of itself and then apply bridge sampling to estimate each normalizing constant separately. This is typically more effective than to artificially bridge the two original densities by augmenting the dimension of the lower one”. I was unsure of the technique this (somehow vague) indication pointed at until I understood that it meant introducing one artificial posterior distribution for each of the parameter spaces and processing each marginal likelihood as an integral ratio in itself. For instance, if 
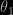



Therefore, the optimal choice of

when 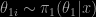


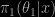
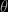

 The boxplot above compares this solution of Meng and Schilling (2002, JASA), called double (because two pseudo-posteriors
The boxplot above compares this solution of Meng and Schilling (2002, JASA), called double (because two pseudo-posteriors 

Comments for València 9
Posted in Statistics, University life with tags Benidorm, comments, discussions, simulations, Valencia 9 on June 23, 2010 by xi'anBernardo, José M. (Universitat de València, Spain)
Integrated objective Bayesian estimation and hypothesis testing. [discussion]
Consonni, Guido (Università di Pavia, Italy)
On moment priors for Bayesian model choice with applications to directed acyclic graphs. [discussion]
Frühwirth-Schnatter, Sylvia (Johannes Kepler Universität Linz, Austria)
Bayesian variable selection for random intercept modeling of Gaussian and non-Gaussian data. [discussion]
Huber, Mark (Claremont McKenna College, USA)
Using TPA for Bayesian inference. [discussion]
Lopes, Hedibert (University of Chicago, USA)
Particle learning for sequential Bayesian computation. [discussion]
Polson, Nicholas (University of Chicago, USA)
Shrink globally, act locally: Sparse Bayesian regularization and prediction. [discussion]
Wilkinson, Darren (University of Newcastle, UK)
Parameter inference for stochastic kinetic models of bacterial gene regulation: a Bayesian approach to systems biology. [discussion]
(with a possible incoming update on Mark Huber’s comments if we manage to get the simulations running in due time).
Share:
9 Comments »