 Answering a question on X validated about a rather standard hierarchical Poisson model, and its posterior Gibbs simulation, where observations are (d and w being a document and a word index, resp.)
Answering a question on X validated about a rather standard hierarchical Poisson model, and its posterior Gibbs simulation, where observations are (d and w being a document and a word index, resp.)
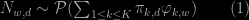
I found myself dragged into an extended discussion on the validation of creating independent Poisson latent variables
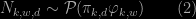
since observing their sum in (1) was preventing the latent variables (2) from being independent. And then found out that the originator of the question had asked on X validated an unanswered and much more detailed question in 2016, even though the notations differ. The question does contain the solution I proposed above, including the Multinomial distribution on the Poisson latent variables given their sum (and the true parameters). As it should be since the derivation was done in a linked 2014 paper by Gopalan, Hofman, and Blei, later published in the Proceedings of the 31st Conference on Uncertainty in Artificial Intelligence (UAI). I am thus bemused at the question resurfacing five years later in a much simplified version, but still exhibiting the same difficulty with the conditioning principles…
